Chapter 4: El núcleo
El núcleo
Opciones de la línea de comandos
Es posible omitir el uso de la GUI e iniciar web2py directamente desde la línea de comandos escribiendo algo como:
python web2py.py -a 'tu contraseña' -i 127.0.0.1 -p 8000
Cuando web2py inicie, creará un archivo llamado "parameters_8000.py" donde se almacenará el hash (la codificación) de la contraseña. Si especificas como contraseña "<ask>", web2py te pedirá que ingreses la contraseña al iniciar.
Para mayor seguridad, puedes iniciar web2py con:
python web2py.py -a '<recycle>' -i 127.0.0.1 -p 8000
En este caso web2py reutiliza la contraseña previamente codificada y almacenada. Si no se provee de una contraseña, o si se ha borrado el archivo "parameters_8000.py", la interfaz administrativa web se deshabilitará.
En algunos sistemas Unix/Linux, si la contraseña es
<pam_user:un_usuario>
web2py usa la contraseña PAM de la cuenta en el Sistema Operativo del usuario especificado para la autenticación como administrador, a menos que la configuración de PAM bloquee el acceso.
Normalmente web2py corre con CPython (la implementación en C del intérprete de Python creada por Guido van Rossum), peró también puede correr con PyPy y Jython. Esta última posibilidad te permite usar web2py en el contexto de una infraestructura J2EE. Para usar Jython, simplemente reemplaza "python web2py.py ..." por "jython web2py.py". Los detalles sobre la instalación de los módulos Jython y zxJDBC requeridos para el acceso a las bases de datos se puede consultar en el Capítulo 14.
El script "web2py.py" puede tomar varios argumentos de la línea de comandos especificando el número máximo de hilos, el uso de SSL, etc. Para una lista completa escribe:
>>> python web2py.py -h
Forma de uso: python web2py.py
Script de inicio del marco de desarrollo web web2py
ADVERTENCIA: si no se especifica una contraseña (-a 'contraseña'),
web2py intentará ejecutar una GUI, en este caso las opciones de
la línea de comandos se omitirán.
Opciones:
--version muestra la versión del programa y sale
-h, --help muestra esta lista de ayuda y sale
-i IP, --ip=IP la dirección IP del servidor (e.g., 127.0.0.1 or ::1);
Nota: Este valor se ignora cuando se usa la opción 'interfaces'.
-p PUERTO, --port=PUERTO puerto del servidor (8000)
-a CONTRASEÑA, --password=CONTRASEÑA
contraseña que se usará para la cuenta administrativa
(usa -a "<recycle>" para reutilizar la última contraseña
almacenada)
-c CERTIFICADO_SSL, --ssl_certificate=CERTIFICADO_SSL
archivo que contiene el certificado ssl
-k CLAVE_PRIVADA_SSL, --ssl_private_key=CLAVE_PRIVADA_SSL
archivo que contiene la clave privada ssl
--ca-cert=CERTIFICADO_CA_SSL
Usa este archivo conteniendo el certificado CA
para validar los certificados X509 de los clientes
-d ARCHIVO_PID, --pid_filename=ARCHIVO_PID
archivo que almacena el pid del servidor
-l ARCHIVO_LOG, --log_filename=ARCHIVO_LOG
archivo para llevar un registro de las conexiones
-n CANTHILOS, --numthreads=CANTHILOS
cantidad de hilos (obsoleto)
--minthreads=MÍNHILOS
número mínimo de hilos del servidor
--maxthreads=MAXHILOS
número máximo de hilos del servidor
-s NOMBRE_SERVIDOR, --server_name=NOMBRE_SERVIDOR
nombre asignado al servidor web
-q TAM_COLA_SOLICITUD, --request_queue_size=REQUEST_QUEUE_SIZE
máximo número de solicitudes en la cola cuando el
servidor no está disponible
-o VENCIMIENTO, --timeout=VENCIMIENTO
tiempo límite de espera para cada solicitud (10 segundos)
-z VENC_CIERRE, --shutdown_timeout=VENC_CIERRE
tiempo límite de espera para cerrar el servidor (5 segundos)
--socket-timeout=VENCIMIENTO_SOCKET
tiempo límite para el ''socket'' (5 segundos)
-f CARPETA, --folder=CARPETA
carpeta desde la cual correrá web2py
-v, --verbose incremento de la salida de depuración de --test
-Q, --quiet deshabilita toda salida
-D NIVEL_DEPURACIÓN, --debug=NIVEL_DEPURACIÓN
establece el nivel de la salida de depuración
(0-100, 0 es todo, 100 es nada; por defecto es 30)
-S NOMBRE_APP, --shell=NOMBRE_APP
corre web2py en la consola shell interactiva de
IPython (si está disponible) con el nombre
especificado de la app (si la app no existe se
creará). NOMBRE_APP tiene el formato a/c/f (c y f
son opcionales)
-B, --bpython corre web2py en la shell interactiva o en bpython (si
se instaló) con el nombre especificado (si no existe
la app se creará). Usa esta opción en combinación con
--shell
-P, --plain usar únicamente la shell de Python; se debería usar
con la opción --shell
-M, --import_models importar automáticamente los archivos del modelo;
por defecto es False; se debería usar con la opción
--shell
-R ARCHIVO_PYTHON, --run=ARCHIVO_PYTHON
correr el archivo de python en un entorno de web2py;
se debería usar con la opción --shell
-K PLANIFICADOR, --scheduler=PLANIFICADOR
correr tareas planificadas para las app especificadas:
lee una lista de nombres de apps del tipo
-K app1,app2,app3 o una lista con grupos como
-K app1:grupo1:grupo2,app2:grupo1 para sobrescribir
nombres específicos de grupos. (solo cadenas, no se
admiten los espacios. Requiere definir un planificador
en los modelos)
-X, --with-scheduler corre el planificador junto con el servidor web
-T RUTA_PRUEBAS, --test=RUTA_PRUEBAS
corre las pruebas ''doctest'' en el entorno de web2py;
RUTA_PRUEBAS tiene el formato a/c/f (c y f son opcionales)
-W SERVICIOWIN, --winservice=SERVICIOWIN
control del servicio de Windows
-W install|start|stop
-C, --cron activa una lista de tareas cron en forma manual;
usualmente se llama desde un crontab del sistema
--softcron activa el uso de softcron
-Y, --run-cron iniciar como proceso en segundo plano
-J, --cronjob identificar un comando iniciado por cron
-L CONFIG, --config=CONFIG
archivo de configuración
-F ARCHIVO_PROFILER, --profiler=ARCHIVO_PROFILER
nombre de archivo del profiler
-t, --taskbar usar la gui de web2py y correr en la barra de
tareas o ''taskbar'' (bandeja del sistema)
--nogui solo texto, sin GUI
-A ARGUMENTOS, --args=ARGUMENTOS se debe completar con una lista de
argumentos a pasarse al script;
se utiliza en conjunto con -S.
-A debe ser la última opción
--no-banner No mostrar la pantalla de inicio
--interfaces=INTERFACES
aceptar conexiones para múltiples direcciones:
"ip1:puerto1:clave1:cert1:ca_cert1;
ip2:puerto2:clave2:cert2:ca_cert2;..."
(:clave:cert:ca_cert es opcional; no debe contener espacios;
las direcciones IPv6 deben llevar corchetes [])
--run_system_tests corre las pruebas para web2py
Las opciones en minúsculas se usan para configurar el servidor web. La opción -L le dice a web2py que lea las opciones de configuración desde un archivo, -W instala web2py como servicio de Windows, mientras que las opciones -S, -P y -M inician una sesión interactiva de la consola de Python. La opción -T busca y ejecuta las pruebas doctest en un entorno de ejecución de web2py. Por ejemplo, el siguiente ejemplo corre los doctest para todos los controladores en la aplicación "welcome":
python web2py.py -vT welcome
Si ejecutas web2py como servicio de Windows, -W, no es conveniente pasar los parámetros de configuración por medio de los argumentos de la línea de comandos. Por esa razón, en la carpeta de web2py se puede ver un ejemplo de archivo de configuración "options_std.py" para el servidor web incorporado:
import socket
import os
ip = '0.0.0.0'
port = 80
interfaces = [('0.0.0.0', 80)]
#,('0.0.0.0',443,'clave_privada_ssl.pem','certificado_ssl.pem')]
password = '<recycle>' # <recycle> significa que se usará la contraseña previamente almacenada
pid_filename = 'servidorhttp.pid'
log_filename = 'servidorhttp.log'
profiler_filename = None
ssl_certificate = None # 'certificado_ssl.pem' # ## ruta al archivo con el certificado
ssl_private_key = None # 'clave_privada_ssl.pem' # ## ruta al archivo con la clave privada
#numthreads = 50 # ## obsoleto; eliminar
minthreads = None
maxthreads = None
server_name = socket.gethostname()
request_queue_size = 5
timeout = 30
shutdown_timeout = 5
folder = os.getcwd()
extcron = None
nocron = None
Este archivo contiene los valores por defecto de web2py, debes importarlo en forma explícita con la opción de línea de comandos -L. Solo funcionará cuando corras web2py como servicio de Windows.
Flujo de trabajo o workflow
El flujo de operación de web2py es el siguiente:
- El servidor web recibe una solicitud HTTP (el servidor web incorporado Rocket u otro servidor web conectado a web2py a través de WSGI u otro adaptador). El servidor web administra cada solicitud en su propio hilo, en forma paralela.
- Se analiza el encabezado HTTP y se pasa al administrador de direcciones (dispatcher, descripto más adelante en este capítulo).
- El administrador de direcciones decide cuál de las aplicaciones manejará la solicitud y asocia la información en PATH_INFO del URL con una llamada a una función. Cada URL se corresponde con una llamada a una función.
- Las solicitudes de archivos de la carpeta static se sirven en forma directa, y los archivos extensos se transmiten al cliente automáticamente usando un stream.
- Toda solicitud que no esté asociada a un archivo estático se asocia a una acción (es decir, a una función en un archivo del controlador, en la aplicación solicitada).
- Antes de llamar a la acción, suceden algunas cosas: si el encabezado de la solicitud contiene una cookie de sesión para la app, se recupera el objeto de la sesión (session), si no, se crea una sesión nueva (pero el archivo de la sesión no se almacenará inmediatamente); se crea un ambiente de ejecución para la solicitud; los modelos se ejecutan en ese entorno.
- Por último, se ejecuta la acción del controlador en el entorno creado previamente.
- Si la acción devuelve una cadena, se devolverá al cliente (o si la acción devuelve un objeto ayudante HTML de web2py, se devolverá la serialización del ayudante).
- Si la acción devuelve un iterable, el cliente recibirá un stream de datos generado por un bucle que recorre ese objeto.
- Si la acción devuelve un diccionario, web2py intentará ubicar la vista para convertir el diccionario. La vista debe tener el mismo nombre que la acción (a menos que se haya especificado otro), y la misma extensión que la página solicitada (por defecto es .html); si se produce una falla, web2py puede recuperar una vista genérica (si está disponible y habilitada). La vista tiene acceso a toda variable definida en los modelos así como también el contenido del diccionario devuelto por la acción, pero no tiene acceso a las variables globales definidas en el controlador.
- La totalidad del código del usuario se ejecuta en el ámbito de una única transacción de la base de datos, a menos que se especifique lo contrario.
- Si el código del usuario finaliza la ejecución con éxito, se aplicarán los cambios en la base de datos.
- Si se produce una falla en la ejecución del código del usuario, la traza del error (error traceback) se almacena en un ticket, y el id del ticket se informa en la respuesta al cliente. Solo el administrador del sistema puede buscar y leer las trazas de error incluidas en los tickets.
Hay algunos detalles a tener en cuenta:
- Los modelos que pertenecen a la misma carpeta se ejecutan en orden alfabético.
- Toda variable definida en el modelo será visible para los otros modelos que le sigan en orden alfabético, para los controladores y para las vistas.
- Los modelos en subcarpetas se ejecutan condicionalmente. Por ejemplo, si el usuario solicitó "a/c/f" donde "a" es la aplicación, "c" el controlador y "f" la función (acción), entonces se ejecutarán los siguientes modelos:
applications/a/models/*.py
applications/a/models/c/*.py
applications/a/models/c/f/*.py- Se ejecutará el controlador solicitado y se llamará a la función solicitada. Esto implica que el código del nivel superior en el controlador también se ejecuta para cada solicitud que corresponda a ese controlador.
- La vista se llama únicamente cuando la acción devuelve un diccionario.
- Si no se encuentra la vista, web2py intenta usar una vista genérica. Por defecto, las vistas genéricas están deshabilitadas, a menos que la app de andamiaje incluya una línea en /models/db.py para habilitarlas restringiéndolas para su uso en localhost. Las vistas genéricas se pueden habilitar en función del tipo de extensión y en función de la acción (usando
response.generic_patterns). En general, las vistas genéricas son una herramienta de desarrollo y normalmente no se deberían usar en producción. Si quieres que algunas acciones usen las vistas genéricas, agrega esas acciones enresponse.generic_patterns(descripto con más detalle en el capítulo dedicado a los servicios).
Los comportamientos posibles para una acción son los siguientes:
Devuelve una cadena
def index(): return 'datos'Devuelve un diccionario para una vista:
def index(): return dict(key='value')Devuelve todas las variables locales:
def index(): return locals()Redirigir al usuario a otra página:
def index(): redirect(URL('otra_accion'))Devolver otra respuesta HTTP distinta a "200 OK":
def index(): raise HTTP(404)Devolver un ayudante (por ejemplo, un FORM):
def index(): return FORM(INPUT(_name='prueba'))(esto se usa más que nada para llamadas de retorno con Ajax y para componentes, para más información puedes consultar el capítulo 12)
Cuando una acción devuelve un diccionario, el diccionario puede contener objetos generados por ayudantes, incluyendo formularios creados a partir de tablas de la base de datos o formularios creados por un creador de formularios o form factory, por ejemplo:
def index(): return dict(formulario=SQLFORM.factory(Field('nombre')).process())(todos los formularios generados por web2py usan el método postback, ver capítulo 3)
Administración de direcciones o Dispatching
web2py asocia los URL con el formato:
http://127.0.0.1:8000/a/c/f.html
con la función f() en el controlador "c.py" de la aplicación "a". Si no se encuentra un f, web2py usa por defecto la función index del controlador. Si no se encuentra un c, entonces web2py usa por defecto el controlador "default.py", y si no se encuentra una aplicación a, web2py usa por defecto la aplicación init. Si no existe una aplicación init, web2py intentará ejecutar la aplicación welcome. Esto se muestra en un esquema en la imagen de abajo:
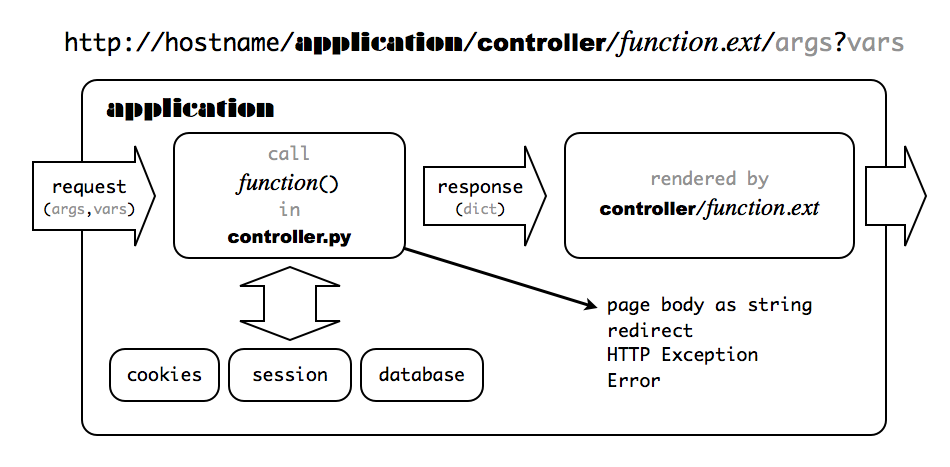
Por defecto, toda nueva solicitud creará una nueva sesión. Además, se devuelve una cookie de sesión al navegador cliente para mantener un registro y control de esa sesión.
La extensión .html es opcional; .html se asume por defecto. La extensión determina la extensión de la vista que procesa y convierte la salida de la función f() del controlador. Esto permite que el mismo contenido se pueda servir en múltiples formatos (html, xml, json, rss, etc.).
Las funciones que toman argumentos o comienzan con un doble guión no se exponen públicamente y solo pueden ser llamadas por otras funciones.
Existe una excepción para el caso de los URL que tienen la forma:
http://127.0.0.1:8000/a/static/nombredearchivo
No hay un controlador llamado "static". web2py interpreta esto como una solicitud de un archivo llamado "nombredearchivo" en la subcarpeta "static" de la aplicación "a".
Además web2py soporta el protocolo IF_MODIFIED, y no envía el archivo si ya se ha almacenado en el caché de navegación y si el archivo no se modificó posteriormente.
Cuando se crea un link a un archivo de audio o video de la carpeta static, si quieres hacer que el navegador descargue el archivo en lugar de hacer una descarga por streamming con un reproductor de medios, agrega ?attachment al URL. Esto le dice a web2py que debe establecer el encabezado Content-Disposition de la respuesta HTTP como "attachment" (adjunto). Por ejemplo:
<a href="/app/static/mi_archivo_de_audio.mp3?attachment">Descargar</a>
Cuando se hace clic en el link de arriba, el navegador le mostrará una opción de descarga del MP3 en lugar de iniciar la transmisión del audio. (Como se detalla más abajo, puedes además establecer los encabezados de la respuesta HTTP directamente almacenando un diccionario con los nombres de los encabezados y sus valores en response.headers.)
http://127.0.0.1:8000/a/c/f.html/x/y/z?p=1&q=2
a una función f en el controlador "c.py" de la aplicación a, y almacena los parámetros del URL en la variable request de la siguiente forma:
request.args = ['x', 'y', 'z']
y:
request.vars = {'p':1, 'q':2}
y también:
request.application = 'a'
request.controller = 'c'
request.function = 'f'
En el ejemplo de arriba, se puede usar tanto request.args[i] como request.args(i) para recuperar el i-ésimo elemento de request.args, la diferencia es que la primera notación genera una excepción cuando la lista no tiene el índice especificado, mientras que la segunda devuelve None en ese caso.
request.url
almacena el URL completo de la solicitud actual (no incluye las variables GET).
request.ajax
por defecto es False pero se establece como True si web2py determina que la acción fue solicitada por medio de Ajax.
Si la solicitud es una solicitud Ajax y fue iniciada por un componente de web2py, el nombre del componente se puede recuperar con:
request.cid
Los componentes se tratan con más detalla en el Capítulo 12.
request.env.request_method se establece como "GET"; si es POST, request.env.request_method tomará el valor "POST", las variables de consulta del URL se almacenan en el diccionario Storage request.vars; también se almacenan en request.get_vars (en el caso de una solicitud POST) o request.post_vars (para solicitudes POST).web2py almacena las variables de su propio entorno y las del entorno WSGI en request.env, por ejemplo:
request.env.path_info = 'a/c/f'
y los encabezados HTTP en variables de entorno, por ejemplo:
request.env.http_host = '127.0.0.1:8000'
Ten en cuenta que web2py valida todos los URL para evitar ataques de tipo "directory traversal".
Los URL sólo pueden contener caracteres alfanuméricos, subguiones y barras; los args (argumentos) pueden contener puntos no consecutivos. Los espacios se reemplazan por subguiones antes de la validación. Si la sintaxis del URL no es válida, web2py devuelve un mensaje con el código de error HTTP 400[http-w] [http-o].
Si el URL corresponde a una solicitud de un archivo estático, web2py simplemente lo lee y transmite el archivo solicitado por medio de un stream.
Si el URL no solicita un archivo estático, web2py procesa la solicitud en el siguiente orden:
- Analiza y recupera las cookie.
- Crea un entorno para ejecutar la función.
- Inicializa los objetos
request,responseycache. - Abre el objeto
sessionexistente o crea uno nuevo. - Ejecuta los modelos que corresponden a la aplicación solicitada.
- Ejecuta la función del controlador que corresponde a la acción solicitada.
- Si la función devuelve un diccionario, ejecuta la vista asociada.
- En caso de finalizar exitosamente, aplica los cambios de las transacciones pendientes.
- Guarda la sesión.
- Devuelve una respuesta HTTP.
Ten en cuenta que el controlador y la vista se ejecutan en distintas copias del mismo entorno; por lo tanto, la vista no puede examinar el controlador, pero si tiene acceso al modelo y a las variables devueltas por la función del controlador correspondiente a la acción.
Si se genera una excepción (que no sea de tipo HTTP), web2py hace lo siguiente:
- Almacena la traza del error en un archivo y le asigna un número de ticket.
- Recupera el estado inicial de todas las transacciones de la base de datos.
- Devuelve una página de error informando el número de ticket.
Si la excepción generada es de tipo HTTP, se interpretará como el comportamiento normal (por ejemplo, una redirección HTTP), y se aplican los cambios a todas las transacciones abiertas. El comportamiento posterior está especificado por el tipo de excepción HTTP mismo. La clase de excepción HTTP no es una excepción estándar de Python; está definida en web2py.
Librerías
Las librerías de módulos de web2py se exponen a las aplicaciones del usuario como objetos del espacio de nombres global. Por ejemplo (request, response, session o cache), clases (ayudantes, validadores, la API de DAL), y funciones (T y redirect).
Estos objetos están definidos en los siguientes archivos:
web2py.py
gluon/__init__.py gluon/highlight.py gluon/restricted.py gluon/streamer.py
gluon/admin.py gluon/html.py gluon/rewrite.py gluon/template.py
gluon/cache.py gluon/http.py gluon/rocket.py gluon/storage.py
gluon/cfs.py gluon/import_all.py gluon/sanitizer.py gluon/tools.py
gluon/compileapp.py gluon/languages.py gluon/serializers.py gluon/utils.py
gluon/contenttype.py gluon/main.py gluon/settings.py gluon/validators.py
gluon/dal.py gluon/myregex.py gluon/shell.py gluon/widget.py
gluon/decoder.py gluon/newcron.py gluon/sql.py gluon/winservice.py
gluon/fileutils.py gluon/portalocker.py gluon/sqlhtml.py gluon/xmlrpc.py
gluon/globals.py gluon/reserved_sql_keywords.py
Observa que muchos de esos módulos, en especial
dal(la capa de abstracción de la base de datos),template(el lenguaje de plantillas),rocket(el servidor web), yhtml(los ayudantes) no tienen dependencias y se pueden usar fuera de web2py.
La app de andamiaje comprimida con tar y gzip que viene con web2py es
welcome.w2p
Esta es creada durante la instalación y se sobrescribe al hacer un upgrade.
Cuando corres web2py por primera vez, se crean dos carpetas: deposit y applications. La carpeta deposit se usa como espacio de almacenamiento temporal para la instalación y desinstalación de aplicaciones.
Si inicias web2py por primera vez y además después de un upgrade, la app "welcome" se comprime en el archivo "welcome.w2p" para usarse como app de andamiaje.
Cuando se hace un upgrade de web2py, esta actualización viene con un archivo llamado "NEWINSTALL". Si web2py encuentra ese archivo, entiende que se ha hecho un upgrade, elimina ese archivo y crea un nuevo archivo "welcome.w2p".
La versión actual de web2py se almacena en el campo "VERSION" y sigue las reglas semánticas estándar para el control de versiones donde el id de la versión del programa (build id) es la fecha y hora (timestamp).
Las pruebas unit-test están en
gluon/tests/
Hay controladores para conexión a varios servidores web:
cgihandler.py # no se recomienda
gaehandler.py # para Google App Engine
fcgihandler.py # para FastCGI
wsgihandler.py # para WSGI
isapiwsgihandler.py # para IIS
modpythonhandler.py # obsoleto
("fcgihandler" utiliza "gluon/contrib/gateways/fcgi.py" desarrollado por Allan Saddi) y
anyserver.pyque es un script para interfaz con distintos tipos de servidor web, descripto en el Capítulo 13.
Hay tres archivos de ejemplo:
options_std.py
routes.example.py
router.example.py
El primero es un archivo con opciones de configuración que se puede pasar a web2py.poy con el parámetro -L. El segundo es un ejemplo de archivo para mapeo de URL (url mapping). Este último se cargará automáticamente cuando se cambie su nombre a "routes.py". El tercero es una sintaxis alternativa para el mapeo de URL, y también se puede renombrar (o copiar como) "routes.py".
Los archivos
app.example.yaml
queue.example.yaml
Son ejemplos de archivos de configuración usados para el despliegue en Google App Engine. Puedes leer más acerca de ellos en el capítulo sobre recetas de implementación y en las páginas de la documentación de Google.
Hay otras librerías adicionales, algunas de ellas son software de terceros:
feedparser[feedparser] de Mark Pilgrim para la lectura fuentes RSS y Atom:
gluon/contrib/__init__.py
gluon/contrib/feedparser.py
markdown2[markdown2] de Trent Mick para el lenguaje de marcado wiki:
gluon/contrib/markdown/__init__.py
gluon/contrib/markdown/markdown2.py
markmin markup:
gluon/contrib/markmin
fpdf creado por Mariano Reingart para la generación de documentos PDF:
gluon/contrib/fpdfEsta librería no está documentada en este texto pero está alojada y documentada aquí:
http://code.google.com/p/pyfpdf/pysimplesoap es una implementación ligera del servidor SOAP creada por Mariano Reingart:
gluon/contrib/pysimplesoap/
simplejsonrpc es cliente para JSON-RPC ligero, también creado por Mariano Reingart:
gluon/contrib/simplejsonrpc.pymemcache[memcache] API Python de Evan Martin:
gluon/contrib/memcache/__init__.py
gluon/contrib/memcache/memcache.pyredis_cache
gluon/contrib/redis_cache.pygql, un port o adaptación de DAL para Google App Engine:
gluon/contrib/gql.py
memdb, una adaptación de DAL que funciona sobre memcache:
gluon/contrib/memdb.py
gae_memcache es una API para el uso de memcache en Google App Engine:
gluon/contrib/gae_memcache.py
pyrtf[pyrtf] para la generación de documentos Rich Text Format (RTF), desarrollado por Simon Cusack y revisado por Grant Edwards:
gluon/contrib/pyrtf/
PyRSS2Gen[pyrss2gen] desarrollado por Dalke Scientific Software, para la crear fuentes de RSS:
gluon/contrib/rss2.py
simplejson[simplejson] de Bob Ippolito, la librería estándar para la lectura, análisis y escritura de objetos JSON:
gluon/contrib/simplejson/
Google Wallet [googlewallet] provee de botones "pagar ahora" enlazados al sistema de procesamiento de pagos de Google:
gluon/contrib/google_wallet.py
Stripe.com [stripe] provee de una API simple para aceptar pagos con tarjeta de crédito:
gluon/contrib/stripe.py
AuthorizeNet [authorizenet] provee de una simple API para aceptar pagos con tarjeta de crédito a través de la red Authorize.net
gluon/contrib/AuthorizeNet.py
Dowcommerce [dowcommerce] API para operaciones con tarjetas de crédito:
gluon/contrib/DowCommerce.py
PaymentTech API para operaciones con tarjetas de crédito:
gluon/contrib/paymentech.py
PAM[PAM] API de autenticación creada por Chris AtLee:
gluon/contrib/pam.py
Un clasificador bayesiano para crear registros ficticios de la base de datos utilizados para pruebas:
gluon/contrib/populate.py
Un archivo con una API para correr aplicaciones en Heroku.com:
gluon/contrib/heroku.py
Un archivo que permite la interacción con la barra de tareas de Windows, cuando web2py corre como servicio:
gluon/contrib/taskbar_widget.py
Métodos opcionales de acceso (login_methods) y formularios (login_form) para la autenticación:
gluon/contrib/login_methods/__init__.py
gluon/contrib/login_methods/basic_auth.py
gluon/contrib/login_methods/browserid_account.py
gluon/contrib/login_methods/cas_auth.py
gluon/contrib/login_methods/dropbox_account.py
gluon/contrib/login_methods/email_auth.py
gluon/contrib/login_methods/extended_login_form.py
gluon/contrib/login_methods/gae_google_account.py
gluon/contrib/login_methods/ldap_auth.py
gluon/contrib/login_methods/linkedin_account.py
gluon/contrib/login_methods/loginza.py
gluon/contrib/login_methods/oauth10a_account.py
gluon/contrib/login_methods/oauth20_account.py
gluon/contrib/login_methods/oneall_account.py
gluon/contrib/login_methods/openid_auth.py
gluon/contrib/login_methods/pam_auth.py
gluon/contrib/login_methods/rpx_account.py
gluon/contrib/login_methods/x509_auth.py
además web2py contiene una carpeta con scripts que pueden ser de ayuda incluyendo
scripts/setup-web2py-fedora.sh
scripts/setup-web2py-ubuntu.sh
scripts/setup-web2py-nginx-uwsgi-ubuntu.sh
scripts/setup-web2py-heroku.sh
scripts/update-web2py.sh
scripts/make_min_web2py.py
...
scripts/sessions2trash.py
scripts/sync_languages.py
scripts/tickets2db.py
scripts/tickets2email.py
...
scripts/extract_mysql_models.py
scripts/extract_pgsql_models.py
...
scripts/access.wsgi
scripts/cpdb.py
Los setup-web2py-* son especialmente útiles porque realizan una instalación y configuración íntegra en ambientes de producción desde cero.
Algunos de ellos se detallan en el Capítulo 14, pero todos incluyen documentación explicando sus características y opciones.
Por último, web2py incluye estos archivos necesarios para crear las distribuciones binarias.
Makefile
setup_exe.py
setup_app.py
Estos son script de configuración para py2exe y py2app, respectivamente, y sólo son requeridos para crear la distribución binaria de web2py. NO ES NECESARIA SU EJECUCIÓN.
Las aplicaciones de web2py contienen archivos adicionales, particularmente librerías de JavaScript, como jQuery, calendar y codemirror. Los créditos para cada proyecto están documentados en sus respectivos archivos.
Applications
Las aplicaciones de web2py se componen de las siguientes partes:
- models describe una representación de la información en función de tablas de la base de datos y relaciones entre tablas.
- controllers describe los algoritmos de la aplicación y su flujo de trabajo.
- views describe cómo la información se debería presentar al usuario usando HTML y JavaScript.
- languages describe cómo traducir las cadenas de la aplicación a los distintos lenguajes soportados.
- static files los archivos estáticos no requieren procesamiento (por ejemplo imágenes, hojas de estilo CSS, etc).
- ABOUT y README son documentos cuyo significado y uso es obvio.
- errors almacena los reportes de errores generados por la aplicación.
- sessions almacena la información relacionada con cada usuario particular.
- databases almacena bases de datos SQLite e información adicional de las tablas.
- cache almacena los ítems de aplicaciones en caché.
- modules son los módulos opcionales Python.
- private los controladores tienen acceso a los archivos privados, mientras que los desarrolladores no pueden acceder a ellos directamente.
- uploads los modelos tienen acceso a los archivos en uploads, pero no están disponibles directamente para el desarrollador (por ejemplo, los archivos subidos por usuarios de la application).
- tests es un directorio para almacenar script de pruebas, y programas fixture o mock.
Se puede acceder a los modelos, vistas, controladores, idiomas y archivos estáticos a través de la interfaz administrativa [design]. También se puede acceder a ABOUT, README y los errores a través de la interfaz administrativa por medio del ítem de menú correspondiente. La aplicación tiene acceso a los archivos de sesión, caché, módulos y privados pero no a través de la interfaz administrativa.
Todo está prolijamente organizado en una clara estructura de directorios que se reproduce en cada aplicación instalada, si bien el usuario no necesita acceder al sistema de archivos en forma directa:
__init__.py ABOUT LICENSE models views
controllers modules private tests cron
cache errors upload sessions static
"__init__.py" es un archivo vacío que es requerido para que Python (y web2py) pueda importar los módulos en el directorio modules.
Observa que la aplicación admin simplemente provee de una interfaz web para las aplicaciones en el sistema de archivos del servidor. Las aplicaciones de web2py también se pueden crear y desarrollar desde la línea de comandos y también puedes desarrollar las aplicaciones usando tu editor preferido de texto o IDE; no estás obligado a usar la interfaz administrativa para navegador. Se puede crear una nueva aplicación en forma manual si se reproduce la estructura de directorio detallada arriba en una subcarpeta, por ejemplo, "applications/nuevaapp/" (o simplemente descomprimiendo con tar el archivo welcome.w2p en tu nuevo directorio de aplicación). Los archivos de aplicaciones también se pueden crear y editar desde la línea de comandos sin necesidad de usar la interfaz admin.
API
Los modelos, controladores y vistas se ejecutan en un entorno para el cual ya se han importado por nosotros los siguientes objetos :
Objetos Globales:
request, response, session, cache
Internacionalización:
T
Navegación:
redirect, HTTP
Ayudantes:
XML, URL, BEAUTIFY
A, B, BODY, BR, CENTER, CODE, COL, COLGROUP,
DIV, EM, EMBED, FIELDSET, FORM, H1, H2, H3, H4, H5, H6,
HEAD, HR, HTML, I, IFRAME, IMG, INPUT, LABEL, LEGEND,
LI, LINK, OL, UL, META, OBJECT, OPTION, P, PRE,
SCRIPT, OPTGROUP, SELECT, SPAN, STYLE,
TABLE, TAG, TD, TEXTAREA, TH, THEAD, TBODY, TFOOT,
TITLE, TR, TT, URL, XHTML, xmlescape, embed64
CAT, MARKMIN, MENU, ON
Formularios y tablas
SQLFORM (SQLFORM.factory, SQLFORM.grid, SQLFORM.smartgrid)Validadores:
CLEANUP, CRYPT, IS_ALPHANUMERIC, IS_DATE_IN_RANGE, IS_DATE,
IS_DATETIME_IN_RANGE, IS_DATETIME, IS_DECIMAL_IN_RANGE,
IS_EMAIL, IS_EMPTY_OR, IS_EXPR, IS_FLOAT_IN_RANGE, IS_IMAGE,
IS_IN_DB, IS_IN_SET, IS_INT_IN_RANGE, IS_IPV4, IS_LENGTH,
IS_LIST_OF, IS_LOWER, IS_MATCH, IS_EQUAL_TO, IS_NOT_EMPTY,
IS_NOT_IN_DB, IS_NULL_OR, IS_SLUG, IS_STRONG, IS_TIME,
IS_UPLOAD_FILENAME, IS_UPPER, IS_URL
Base de datos:
DAL, Field
Para compatibilidad hacia atrás SQLDB=DAL y SQLField=Field. Te recomendamos que uses la nueva sintaxis DAL y Field, en lugar de la anterior.
También se definen otros objetos y módulos en las librerías, pero estos no se importan automáticamente, ya que no se usan con tanta frecuencia. Los objetos esenciales de la API en el entorno de ejecución de web2py son request, response, session, cache, URL, HTTP, redirect y T y se detallan abajo.
Algunos objetos y funciones, incluyendo Auth, Crud y Service , están definidos en "gluon/tools.py" y se deben importar cuando se los requiere:
from gluon.tools import Auth, Crud, Service
Acceso a la API desde módulos de Python
Tus módulos o controladores pueden importar módulos de Python, y estos pueden necesitar el uso de alguna parte de la API de web2py. La forma de hacer esto es importando esas partes:
from gluon import *De hecho, cualquier módulo de Python, incluso cuando no se importe en el entorno de ejecución de web2py, puede importar la API de web2py siempre y cuando web2py esté incluido en el sys.path.
Sin embargo, existe una particularidad. web2py define algunos objetos globales (request, response, session, cache, T) que sólo pueden existir cuando hay una solicitud HTTP disponible (o simulada). Por lo tanto, los módulos pueden acceder a ellos sólo si se han llamado desde una aplicación. Por esta razón se incluyen en un contenedor llamado current, que es un objeto que pertenece al dominio de un hilo (thread local). Aquí hay un ejemplo:
Crear un módulo "/miapp/modules/prueba.py" que contenga:
from gluon import *
def ip(): return current.request.clientAhora desde un controlador en "miapp" se puede hacer:
import test
def index():
return "Tu ip es " + test.ip()Algunas cosas a tener en cuenta:
import testbusca el módulo inicialmente en la carpeta modules de la app, luego en las carpetas listadas ensys.path. Por eso, los módulos del nivel de la aplicación siempre tienen precedencia sobre módulos de Python. Esto permite que distintas app incluyan distintas versiones de sus módulos, sin conflictos.- Los distintos usuarios pueden llamar a la misma acción
indexsimultáneamente, que llama a la función en el módulo, y sin embargo no hay conflicto porquecurrent.requestes un objeto diferente para distintos hilos. Sólo ten cuidado de no acceder acurrent.requestfuera de funciones o clases (por ejemplo en el nivel más general) en el módulo. import testes un atajo defrom applications.nombreapp.modules import test. Al usar la sintaxis más larga, es posible importar módulos desde otras aplicaciones.
Para mantener la uniformidad con el comportamiento estándar de Python, por defecto web2py no vuelve a cargar módulos cuando se realizan cambios. De todos modos esto se puede cambiar. Para habilitar la recarga automática de módulos, utiliza la función track_changes como sigue (típicamente en un módulo, antes de cualquier import):
from gluon.custom_import import track_changes; track_changes(True)
De ahora en más, cada vez que un módulo se importe, la funcionalidad de importación revisará si el archivo de código fuente (.py) ha cambiado. Si se detectan cambios, se cargará el módulo nuevamente.
No debes llamar a track_changes en los módulos en sí.
Track changes sólo comprueba cambios para módulos que se almacenan en la aplicación.
Los módulos que importan current tienen acceso a:
current.requestcurrent.responsecurrent.sessioncurrent.cachecurrent.T
y a cualquier otra variable que tu aplicación decida almacenar en current. Por ejemplo un modelo podría hacer esto:
auth = Auth(db)
from gluon import current
current.auth = auth
y ahora todos los módulos importados tienen acceso a current.auth.
current e import proveen de un poderoso mecanismo para crear módulos ampliables y reutilizables para tus aplicaciones.
Hay un detalle importante a tener en cuenta. Dado un
from gluon import current, es correcto el uso decurrent.requesto cualquiera de los demás objetos locales del hilo pero uno nunca debería pasarlos a variables globales en el módulo, como enrequest = current.request # ¡INCORRECTO! ¡PELIGRO!ni debería pasarlos a atributos de clase
class MyClass: request = current.request # ¡INCORRECTO! ¡PELIGRO!Esto se debe a que los objetos locales del hilo deben extraerse en tiempo de ejecución. Las variables globales, en cambio, se definen una sola vez cuando el modelo se importa inicialmente.
Hay otro problema relacionado con el caché. No se puede usar el objeto cache para decorar funciones en los módulos, esto se debe a que el comportamiento no sería el esperado. Para poder hacer un caché de la función f en un módulo debes usar lazy_cache:
from gluon.cache import lazy_cache
lazy_cache('clave', time_expire=60, cache_model='ram')
def f(a, b, c): ....
Ten en cuenta que la clave está definida por el usuario pero debe estar identificada estrictamente con la función. Si se omite la clave, web2py la determinará automáticamente.
request
El objeto request es una instancia de la clase omnipresente llamada gluon.storage.Storage, que extiende la clase dict de Python. Básicamente se trata de un diccionario, pero los valores de cada ítem también pueden obtenerse como atributos:
request.vars
es lo mismo que:
request['vars']
A diferencia de un diccionario, si un atributo (o clave) no existe, Storage no genera una excepción: en su lugar devuelve None.
A veces es de utilidad crear nuestros propios objetos Storage. Puedes hacerlo de la siguiente forma:
from gluon.storage import Storage mi_storage = Storage() # objeto Storage vacío mi_otro_storage = Storage(dict(a=1, b=2)) # convertir un diccionario a Storage
request tiene los siguientes ítems/atributos, de los cuales algunos son también instancias de la clase Storage:
request.cookies: un objetoCookie.SimpleCookie()que contiene las cookie pasadas con la solicitud HTTP. Se comporta como un diccionario compuesto por cookie. Cada cookie es un objeto Morsel[morsel].request.env: un objetoStorageque contiene las variables de entorno pasadas al controlador, incluyendo las variables del encabezado HTTP de la solicitud y los parámetros WSGI estándar. Las variables de entorno se convierten a minúsculas, y los puntos se convierten a subguiones para mejorar la memorización.request.application: el nombre de la aplicación solicitada.request.controller: el nombre del controlador solicitado.request.function: el nombre de la función solicitada.request.extension: la extensión de la acción solicitada. Por defecto es "html". Si la función del controlador devuelve un diccionario y no especifica una vista, esto es usado para determinar la extensión del archivo de la vista que convertirá (render) el diccionario (extraída derequest.env.path_info).request.folder: el directorio de la aplicación. Por ejemplo si la aplicación es "welcome",request.folderse establece como la ruta absoluta "ruta/a/welcome". En tus programas, deberías usar siempre esta variable y la funciónos.path.joinpara obtener rutas a los archivos que quieras manipular. Si bien web2py usa siempre rutas absolutas, es una buena práctica no cambiar explícitamente el directorio en uso (current working directory) sea cual sea, ya que no es una práctica segura para el trabajo con hilos (thread-safe).request.now: un objetodatetime.datetimeque almacena la hora y la fecha de la solicitud actual.request.utcnow: un objetodatetime.datetimeque almacena la hora y fecha UTC de la solicitud actual.request.args: Una lista de los componentes de la ruta de la URL que siguen después del nombre de la función del controlador; equivalente arequest.env.path_info.split('/')[3:]request.vars: un objetogluon.storage.Storageque contiene las variables de la consulta para HTTP GET y HTTP POST.request.get_vars: un objetogluon.storage.Storageque contiene sólo las variables de la consulta para HTTP GET.request.post_vars: un objetogluon.storage.Storageque contiene sólo las variables de la consulta para HTTP POST.request.client: La dirección ip del cliente determinada por, si se detectó,request.env.http_x_forwarded_foro porrequest.env.remote_addrde lo contrario. Si bien esto es útil no es confiable porque elhttp_x_forwarded_forse puede falsificar.request.is_local:Truesi el cliente está en localhost,Falseen su defecto. Debería de funcionar detrás de un proxy si el proxy soportahttp_x_forwarded_for.request.is_https:Truesi la solicitud utiliza el protocolo HTTPS,Falseen su defecto.request.body: un stream de archivo de sólo-lectura conteniendo el cuerpo de la solicitud HTTP. Esto se lee (parse) automáticamente para obtener elrequest.post_varspara luego devolverse a su estado inicial. Se puede leer conrequest.body.read().request.ajaxes True si la función se llamó desde una solicitud tipo Ajax.request.cides eliddel componente que generó la solicitud Ajax (en caso de existir). Puedes leer más acerca de componentes en el Capítulo 12.request.requires_https()evita que se ejecute todo comando si la solicitud no se realizó utilizando HTTPS y redirige al visitante a la actual página usando ese protocolo.request.restfuleste es un decorador nuevo y realmente útil que se puede usar para cambiar el comportamiento por defecto de una acción de web2py separando las solicitudes según GET/POST/PUSH/DELETE. Se tratará con cierto detalle en el Capítulo 10.request.user_agent()extrae (parse) el campo user_agent del cliente y devuelve la información en forma de diccionario. Es útil para la detección de dispositivos móviles. Utiliza "gluon/contrib/user_agent_parser.py" creado por Ross Peoples. Para ver como funciona, prueba incrustando el siguiente código en una vista:
{{=BEAUTIFY(request.user_agent())}}
request.global_settingsrequest.global_settingscontiene parámetros de configuración general de web2py. Estos parámetros se establecen automáticamente y no deberías cambiarlos. Por ejemplorequest.global_settings.gluon_parentcontiene la ruta completa a la carpeta de web2py,request.global_settings.is_pypydetermina si web2py está corriendo en PyPy.request.wsgies un hook que te permite llamar a aplicaciones WSGI de terceros en el interior de las acciones
El último incluye:
request.wsgi.environrequest.wsgi.start_responserequest.wsgi.middleware
su uso se trata al final de este Capítulo.
Como ejemplo, la siguiente llamada en un sistema típico:
http://127.0.0.1:8000/examples/default/status/x/y/z?p=1&q=2
resulta en el siguiente objeto request:
| variable | valor |
request.application | examples |
request.controller | default |
request.function | index |
request.extension | html |
request.view | status |
request.folder | applications/examples/ |
request.args | ['x', 'y', 'z'] |
request.vars | <Storage {'p': 1, 'q': 2}> |
request.get_vars | <Storage {'p': 1, 'q': 2}> |
request.post_vars | <Storage {}> |
request.is_local | False |
request.is_https | False |
request.ajax | False |
request.cid | None |
request.wsgi | <hook> |
request.env.content_length | 0 |
request.env.content_type | |
request.env.http_accept | text/xml,text/html; |
request.env.http_accept_encoding | gzip, deflate |
request.env.http_accept_language | en |
request.env.http_cookie | session_id_examples=127.0.0.1.119725 |
request.env.http_host | 127.0.0.1:8000 |
request.env.http_referer | http://web2py.com/ |
request.env.http_user_agent | Mozilla/5.0 |
request.env.path_info | /examples/simple_examples/status |
request.env.query_string | remote_addr:127.0.0.1 |
request.env.request_method | GET |
request.env.script_name | |
request.env.server_name | 127.0.0.1 |
request.env.server_port | 8000 |
request.env.server_protocol | HTTP/1.1 |
request.env.server_software | Rocket 1.2.6 |
request.env.web2py_path | /Users/mdipierro/web2py |
request.env.web2py_version | Version 2.4.1 |
request.env.wsgi_errors | <open file, mode 'w' at > |
request.env.wsgi_input | |
request.env.wsgi_url_scheme | http |
Según el servidor web, se establecerán unas u otras de las variables de entorno. Aquí nos basamos en el servidor wsgi incorporado Rocket. El conjunto de variables no difiere en mucho cuando se utiliza el servidor web Apache.
Las variables de request.env.http_* se extraen del encabezado HTTP de la solicitud.
Las variables de request.env.web2py_* no se extraen del entorno del servidor web, sino que son creadas por web2py en caso de que la aplicación necesite saber acerca de la versión y ubicación de web2py, y si está corriendo en el Google App Engine (porque algunas optimizaciones específicas podrían ser necesarias).
Se deben tener en cuenta además las variables de request.env.wsgi_*, que son específicas del adaptador wsgi.
response
response es otra instancia de la clase Storage, que contiene lo siguiente:
response.body: Un objetoStringIOen el que web2py escribe el cuerpo de la página devuelta. NUNCA MODIFIQUES ESTA VARIABLE.response.cookies: es similar arequest.cookies, pero mientras el último contiene las cookie enviadas desde el cliente al servidor, el primero contiene las cookie enviados desde el servidor al cliente. La cookie de la sesión se maneja automáticamente.response.download(request, db): un método usado para implementar la función del controlador que permite descargar los archivos subidos.request.downloadusa el último argumento enrequest.argspara recuperar el nombre codificado del archivo (por ejemplo, el nombre del archivo generado cuando se subió al servidor y almacenado en el campo upload). Este método extrae el nombre del campo upload y el nombre de la tabla así como también el nombre del archivo original del nombre de archivo codificado.response.dowloadrecibe dos argumentos opcionales:chunk_sizeconfigura el tamaño en byte para streaming por partes (chunked streaming, por defecto es 64K), yattachmentsdetermina si el archivo descargado debería tratarse como attachment o no (por defectoTrue). Ten en cuenta queresponse.downloadse usa específicamente para la descarga de archivos asociados a campos upload de la base de datos. Usaresponse.stream(ver abajo) para otras clases de descargas de archivos y streaming. Además, ten en cuenta que no es necesario el uso deresponse.downloadpara examinar los archivos subidos a la carpeta static -- los archivos estáticos pueden (y deberían en general) examinarse directamente a través de su URL (por ejemplo, /app/static/files/miarchivo.pdf).response.files: una lista de archivos .css, .js, .coffee, y .less asociados a la página. Se añadirán automáticamente en el encabezado de la plantilla general "layout.html" a través de la vista incluida "web2py_ajax.html". Para añadir nuevos archivos CSS, JS, COFFEE, o LESS, basta con agregarlos a la lista. Se detectan los archivos duplicados. El orden es relevante.response.include_files()genera etiquetas del encabezado html para incluir todos los archivos enresponse.files(utilizado por "views/web2py_ajax.html").response.flash: parámetro opcional que puede incluirse en las vistas. Normalmente se usa para notificar al usuario sobre algo que ha ocurrido.response.headers: undictpara los encabezados de la respuesta HTTP. web2py establece algunos encabezados por defecto, incluyendo "Content-Length", "Content-Type", y "X-Powered-By" (que se especifica como web2py). Además, web2py establece el valor de los encabezados "Cache-Control", "Expires", y "Pragma" para prevenir el cacheado del lado del cliente, excepto para las solicitudes de archivos estáticos, para los cuales la opción de cacheado se habilita. Los encabezados que web2py establece se pueden sobrescribir o eliminar, y es posible añadir nuevos encabezados (por ejemplo,response.headers['Cache-Control'] = 'private'). Puedes eliminar un encabezado por su clave en el diccionario response.headers, por ejemplo condel response.headers['Custom-Header'], sin embargo, los encabezados por defecto de web2py se agregarán nuevamente antes de devolver la respuesta. Para evitar este comportamiento, debes establecer el valor del encabezado como None, por ejemplo, para eliminar el encabezado Content-Type por defecto, usaresponse.headers['Content-Type'] = Noneresponse.menu: parámetro opcional que se puede incluir en las vistas, normalmente para pasar un árbol de menús de navegación a la vista. Esto puede ser convertido (render) por el ayudante MENU.response.meta: un objeto Storage (similar a un diccionario) que contiene información de tipo<meta>opcional comoresponse.meta.author,.description, y/o.keywords. El contenido de cada variable meta se inserta automáticamente en la etiquetaMETAcorrespondiente a través del código en "views/web2py_ajax.html", que se incluye en "views/layout.html".response.include_meta()genera una cadena que incluye todos los encabezadosresponse.metaserializados (usado por "views/web2py_ajax.html").response.postprocessing: esta es una lista de funciones, vacías por defecto. Estas funciones se usan para filtrar el objeto response en la salida de una acción, antes de que la salida sea convertida (render) por la vista. Se podría utilizar para implementar el soporte de otros lenguajes de plantillas.response.render(vistas, variables): un método usado para llamar a la vista en forma explícita en el controlador.vistaes un parámetro opcional que especifica el nombre del archivo de la vista,variableses un diccionario de valores asignados a nombres que se pasan a la vista.response.session_file: stream de archivo que contiene la sesión.response.session_file_name: el nombre del archivo donde se guardará la sesión.response.session_id: el id de la sesión actual. Se detecta automáticamente. NUNCA CAMBIES ESTA VARIABLE.response.session_id_name: el nombre de la cookie de sesión para la app actual. NUNCA CAMBIES ESTA VARIABLE.response.status: el número entero del código de status HTTP que se pasa en la respuesta. Por defecto es 200 (OK).response.stream(archivo, chunk_size, request=request, attachment=False, filename=None, headers=None): cuando un controlador devuelve este objeto, web2py crea un stream con el contenido para el cliente en bloques del tamaño especificado enchunk_size. El parámetrorequestes obligatorio para utilizar el inicio del paquete en el encabezado HTTP. Como se señala más arriba,response.downloaddebería usarse para recuperar archivos almacenados a través del campo upload. Para otros casos se puede usarresponse.stream, como el envío de un archivo temporario u objeto StringIO creado en el controlador.
Si attachment es True, el encabezado Content-Disposition se establecerá como "attachment", y si se pasa el nombre del archivo, también se agregará a ese encabezado (pero sólo cuando attachment sea True). Si no se incluyen previamente en response.headers, los siguientes encabezados de la respuesta se establecerán automáticamente: Content-Type, Content-Length, Cache-Control, Pragma y Last-Modified (los últimos tres se establecen para permitir el caché del archivo en el navegador). Para sobrescribir cualquiera de estos encabezados automáticos, simplemente configúralos en response.headers antes de llamar a response.stream.
response.subtitle: parámetro opcional que se puede incluir en las vistas. Debería contener el subtítulo de la página.response.title: parámetro opcional que se puede incluir en las vistas. Debería contener el título de la página y debería ser convertido (render) para el objeto HTML TAG del título en el encabezado.response.toolbar: una función que te permite embeber una barra de herramientas en la página para depuración{{=response.toolbar()}}. La barra de herramientas muestra las variables de request, response, session y el tiempo de acceso a la base de datos para cada consulta.response._vars: se puede acceder a esta variable solamente desde una vista, no en la acción. Contiene los valores devueltos por la acción a la vista.response._caller: esta es una función que envuelve todas las llamadas de la acción. Por defecto es la función idéntica, pero se puede modificar para poder manejar ciertas clases de excepción y registrar información adicional;response._caller = lambda f: f()
response.optimize_css: se puede establecer como "concat,minify,inline" para concatenar, simplificar y alinear los archivos CSS incluidos con web2py.response.optimize_js: se puede establecer como "concat,minify,inline" para concatenar, simplificar y alinear los archivos JavaScript incluidos con web2py.response.view: el nombre de la plantilla que debe convertir (render) la página. Por defecto es:
"%s/%s.%s" % (request.controller, request.function, request.extension)
o, si este archivo no se encuentra:
"generic.%s" % (request.extension)
Cambia el valor de esta variable para modificar el archivo la vista asociado a una acción particular.
response.delimiterspor defecto('{{','}}'). Te permite cambiar los delimitadores de código incrustado en las vistas.response.xmlrpc(request, methods): si un controlador devuelve este tipo de objeto, la función expone los métodos a través de XML-RPC[xmlrpc]. Esta función es obsoleta ya que se ha implementado un mecanismo mejor y se detalla en el Capítulo 10.response.write(text): un método para escribir texto en el cuerpo de la página de la salida.response.jspuede contener código JavaScript. Este código se ejecutará si y sólo si la respuesta es recibida por un componente de web2py, según se detalla en el capítulo 12.
Como response es un objeto gluon.storage.Storage, se puede usar para almacenar otros atributos que quieras pasar a la vista. Si bien no hay una restricción técnicamente, lo recomendable es almacenar sólo las variables que se vayan a convertir (render) en todas las páginas en la plantilla general ("layout.html").
De todos modos, es muy recomendable que el uso esté restringido a las variables que se listan aquí:
response.title
response.subtitle
response.flash
response.menu
response.meta.author
response.meta.description
response.meta.keywords
response.meta.*
porque esto hará mucho más fácil la tarea de reemplazar el archivo "layout.html" que viene con web2py por otra plantilla, una que use las mismas variables.
Las versiones antiguas de web2py usaban response.author en lugar de response.meta.author y un formato similar para el resto de los atributos meta.
session
session es otra instancia de la clase Storage. Se puede almacenar cualquier cosa en ella, por ejemplo:session.myvariable = "hola"
se puede recuperar más tarde:
a = session.mivariable
Siempre que el código se ejecute durante la misma sesión para el mismo usuario (suponiendo que el usuario no eliminó las cookie de la sesión y la sesión no venció). Al ser session un objeto Storage, el intento fallido de acceder a atributos o nombres no establecidos no genera una excepción: en su lugar devuelve None.
El objeto session tiene tres métodos importantes. Uno es forget:
session.forget(response)
Este le dice a web2py que no guarde la sesión. Este método debería usarse en los controladores cuyas acciones se llamen a menudo y no requieran el registro de la actividad del usuario. session.forget() impide la escritura del archivo session, sin importar si se ha modificado o no. session.forget(response) adicionalmente desbloquea y cierra el archivo de la sesión. Difícilmente necesites llamar a este método ya que las sesiones no se guardan cuando no han cambiado. Sin embargo, si la página hace múltiples solicitudes Ajax simultaneas, es buena idea que las acciones llamadas vía Ajax utilicen session.forget(response) (siempre que la acción no necesite la sesión). De lo contrario, cada acción Ajax tendrá que esperar a la anterior a que se complete (y a que el archivo de la sesión se desbloquee) antes de continuar, haciéndose más lenta la descarga de la página. Ten en cuenta que las sesiones no se bloquean cuando se almacenan en la base de datos.
Otro método es:
session.secure()
que le dice a web2py que establezca la cookie de la sesión para que sea segura. Esto se debería configurar si la app corre sobre https. Al configurar la cookie de sesión como segura, el servidor le informa al navegador que no envíe la cookie de regreso al servidor a menos que la conexión sea sobre https.
El otro método es connect. Por defecto las sesiones se almacenan en el sistema de archivos y la cookie de la sesión se usa para almacenar y recuperar el session.id. Usando el método connect es posible decirle a web2py que almacene las sesiones en la base de datos o en las cookie, eliminando de esa forma la necesidad de usar el sistema de archivos para el manejo de las sesiones.
Por ejemplo, para guardar las sesiones en la base de datos:
session.connect(request, response, db, masterapp=None)
donde db es el nombre de una conexión a base de datos abierta (como las que genera la DAL). Esto le dice a web2py que queremos almacenar las sesiones en la base de datos y no en el sistema de archivos. session.connect se debe ubicar luego de db=DAL(...), pero antes que cualquier otro algoritmo que utilice la sesión, por ejemplo, la configuración inicial de Auth.
web2py crea una tabla:
db.define_table('web2py_session',
Field('locked', 'boolean', default=False),
Field('client_ip'),
Field('created_datetime', 'datetime', default=now),
Field('modified_datetime', 'datetime'),
Field('unique_key'),
Field('session_data', 'text'))
y almacena una sesión cPickleada en el campo session_data.
La opción masterapp=None, por defecto, le dice a web2py que intente recuperar una sesión existente para la aplicación con el nombre en request.application, en la aplicación actual.
Si deseas que una o más aplicaciones compartan las sesiones, establece el valor de masterapp con el nombre de la aplicación maestra.
Para almacenar sesiones en cookie en cambio puedes hacer:
session.connect(request, response, cookie_key='yoursecret', compression_level=None)
Aquí cookie_key es una clave de cifrado simétrico (symmetric encryption key). compression_level es un nivel de cifrado zlib opcional.
Si bien las sesiones en las cookie son frecuentemente recomendables por razones de escalabilidad, son limitados en tamaño. Las sesiones pesadas producirán fallas en las cookie.
Puedes revisar el estado de tu aplicación en todo momento mostrando la salida de las variables del sistema request, session y response. Una forma de hacer esto es creando una acción especial:
def status():
return dict(request=request, session=session, response=response)
En la vista "generic.html" esto se puede hacer usando {{=response.toolbar()}}.
Separando sesiones
Si almacenas las sesiones en sistemas de archivos y manejas una cantidad importante, el sistema de archivos puede convertirse un cuello de botella, una forma de resolver esto es la siguiente:
session.connect(request, response, separate=True)
Al establecer separate=True web2py almacenará las sesiones no en la carpeta sessions/sino en distintas subcarpetas de esa ruta. Cada subcarpeta se creará automáticamente. Las sesiones con el mismo prefijo se ubicarán en la misma carpeta. Nuevamente, ten en cuenta que esto se debe ejecutar antes de cualquier otro algoritmo que utilice el objeto session.
cache
cache es un objeto global que también está disponible en el entorno de ejecución de web2py. Tiene dos atributos:cache.ram: el caché de la aplicación en la memoria principal.cache.disk: el caché de la aplicación en el disco.
se pueden hacer llamadas a cache (es un callable), esto le permite ser usado como decorador para el caché de acciones y vistas.
El siguiente ejemplo guarda en caché la función time.ctime() en la RAM:
def cache_en_ram():
import time
t = cache.ram('tiempo', lambda: time.ctime(), time_expire=5)
return dict(tiempo=t, link=A('clic aquí', _href=request.url))
La salida de lambda: time.ctime() se guarda en caché en RAM por 5 segundos. La cadena 'tiempo' se usa como clave del caché.
El ejemplo siguiente guarda en caché la función time.ctime() en disco:
def cache_en_disco():
import time
t = cache.disk('tiempo', lambda: time.ctime(), time_expire=5)
return dict(tiempo=t, link=A('clic aquí', _href=request.url))
La salida de lambda: time.ctime() se guarda en caché en el disco (usando el módulo shelve) por 5 segundos.
Ten en cuenta que el segundo argumento de cache.ram y cache.disk debe ser una función u objeto que admita llamadas (callable). Si quieres guardar en caché un objeto existente en lugar de la salida de una función, puedes simplemente devolverlo por medio de una función lambda:
cache.ram('miobjeto', lambda: miobjeto, time_expire=60*60*24)
El próximo ejemplo guarda en caché la función time.ctime() tanto en RAM como en el disco:
def cache_en_ram_y_disco():
import time
t = cache.ram('tiempo', lambda: cache.disk('tiempo',
lambda: time.ctime(), time_expire=5),
time_expire=5)
return dict(tiempo=t, link=A('clic aquí', _href=request.url))
La salida de lambda: time.ctime() se guarda en caché en el disco (usando el módulo shelve) y luego en RAM por 5 segundos. web2py busca en el RAM primero y si no está allí busca en el disco. Si no está en RAM o en el disco, lambda: time.ctime() se ejecuta y se actualiza el caché. Esta técnica es de utilidad en un entorno de procesos múltiples (multiprocess). Los dos objetos tiempo no necesariamente deben ser iguales.
El siguiente ejemplo guarda en caché en RAM la salida de la función del controlador (pero no la vista):
@cache(request.env.path_info, time_expire=5, cache_model=cache.ram)
def cache_del_controlador_en_ram():
import time
t = time.ctime()
return dict(tiempo=t, link=A('clic aquí', _href=request.url))
El diccionario devuelto por cache_del_controlador_en_ram se guarda en caché durante 5 segundos. Ten en cuenta que el resultado de un select de la base de datos no se puede guardar en caché sin una serialización previa. Una forma más apropiada es guardar el select de la base de datos directamente en caché por medio del argumento chache del método select.
El siguiente ejemplo guarda en caché la salida de la función del controlador en el disco (pero no la vista):
@cache(request.env.path_info, time_expire=5, cache_model=cache.disk)
def cache_del_controlador_en_disco():
import time
t = time.ctime()
return dict(tiempo=t, link=A('clic para refrescar',
_href=request.url))
El diccionario devuelto por cache_del_controlador_en_disco se guarda en caché en el disco por 5 segundos. Recuerda que web2py no puede guardar en caché un diccionario que contenga objetos que no se puedan picklear.
Además es posible guardar la vista en el caché. El truco consiste en convertir (render) la vista en la función del controlador, para que el controlador devuelva una cadena. Esto se hace devolviendo response.render(d), donde d es el diccionario que queremos pasar a la vista. El siguiente ejemplo guarda en caché la salida de la función del controlador en RAM (incluyendo la vista convertida):
@cache(request.env.path_info, time_expire=5, cache_model=cache.ram)
def cache_de_controlador_y_vista():
import time
t = time.ctime()
d = dict(time=t, link=A('Clic para refrescar', _href=request.url))
return response.render(d)
response.render(d) devuelve la vista convertida como cadena, que ahora se guarda en caché por 5 segundos. Esta es la mejor y la más rápida forma de usar el caché.
Ten en cuenta que time_expire se usa para comparar la hora actual con la hora en la que el objeto solicitado fue almacenado en caché por última vez. No afecta a las solicitudes posteriores. Esto permite a time_expire establecerse dinámicamente cuando se solicita un objeto en lugar en lugar de tomar un valor fijo cuando se guarda el objeto. Por ejemplo:
mensaje = cache.ram('mensaje', lambda: 'Hola', time_expire=5)
Ahora, supongamos que la siguiente llamada se hace 10 segundos después de la llamada de arriba:
mensaje = cache.ram('mensaje', lambda: 'Adiós', time_expire=20)
Como time_expire se establece en 20 segundos en la segunda llamada y sólo han transcurrido 10 segundos desde la primera vez que se ha guardado el mensaje, se recuperará el valor "Hola" de el caché, y no se actualizará con "Adiós". El valor de time_expire de 5 segundos en la primera llamada no tiene impacto en la segunda llamada.
Al configurar time_expire=0 (o usando un valor negativo), se fuerza la actualización del ítem en caché (porque el tiempo transcurrido desde el último almacenamiento será siempre > 0), y si se configura time_expire=None se fuerza la recuperación del valor en caché, sin importar el tiempo transcurrido desde la última vez que se guardó (si time_expire es siempre None, se impide efectivamente el vencimiento del ítem en caché).
Puedes borrar una o más variables de caché con
cache.ram.clear(regex='...')
donde regex es una expresión regular (regular expression) que especifica todas las palabras que quieras eliminar del caché. También puedes eliminar un sólo ítem con:
cache.ram(clave, None)
donde clave es la palabra asociada al ítem en caché.
Además es posible definir otros mecanismos de caché como memcache. Memcache está disponible con gluon.contrib.memcache y se trata con más detalle en el Capítulo 14.
Ten cuidado con el caché porque usualmente trabaja en el nivel de la aplicación, no en el nivel de usuario. Si necesitas, por ejemplo, guardar en caché contenido específico del usuario, utiliza una clave que incluya el id de ese usuario.
URL
La función URL es una de las más importantes de web2py. Genera URL de rutas internas para las acciones y los archivos estáticos.
Aquí hay un ejemplo:
URL('f')
se asocia (map) a
/[aplicación]/[controlador]/f
Ten en cuenta que la salida de la función URL depende del nombre de la aplicación actual, el controlador que se llamó y otros parámetros. web2py soporta URL mapping y URL mapping inverso. El URL mapping o mapeo de URL te permite redefinir el formato de las URL externas. Si usas la función URL para generar todas las URL internas, entonces los agregados o modificaciones no presentarán vínculos incorrectos (broken links) en el ámbito de la aplicación.
Puedes pasar parámetros adicionales a la función URL, por ejemplo, palabras extra en la ruta del URL (args) y variables de consulta (query variables):
URL('f', args=['x', 'y'], vars=dict(z='t'))
se asocia (mapea) a
/[aplicación]/[controlador]/f/x/y?z=t
Los atributos arg son leídos (parse), decodificados y finalmente almacenados automáticamente en request.args por web2py. De forma similar ocurre con las variables de consulta que se almacenan en request.vars. args y vars proveen de un mecanismo básico usado por web2py para el intercambio de información con el navegador cliente.
Si args contiene sólo un elemento, no hace falta que se pase como lista.
Además puedes usar la función URL para generar las URL de acciones en otros controladores o aplicaciones:
URL('a', 'c', 'f', args=['x', 'y'], vars=dict(z='t'))
se asocia (map) a
/a/c/f/x/y?z=tAdemás es posible especificar una aplicación, controlador y función usando argumentos con nombre (named arguments):
URL(a='a', c='c', f='f')
Si no se especifica el nombre de la aplicación se asume la app actual.
URL('c', 'f')
Si falta el nombre del controlador, se asume el actual.
URL('f')
En lugar de pasar el nombre de una función del controlador también es posible pasar la función en sí
URL(f)
Por las razones expuestas más arriba, deberías utilizar siempre la función URL para generar los URL de archivos estáticos para tus aplicaciones. Los archivos estáticos se almacena en la subcarpeta static de la aplicación (es ese el lugar que se les asigna cuando se suben a través de la interfaz administrativa). web2py provee de un controlador virtual 'static' que tiene la tarea de recuperar los archivos de la subcarpeta static, determinar su tipo de contenido, y crear el stream del archivo para el cliente. El siguiente ejemplo genera una URL para la imagen estática "imagen.png":
URL('static', 'imagen.png')
se asocia (map) a
/[aplicación]/static/imagen.png
Si la imagen estática está en una subcarpeta incluida en la carpeta static, puedes incluir la/s subcarpeta/s como parte del nombre del archivo. Por ejemplo, para generar:
/[aplicación]/static/imagenes/iconos/flecha.pnguno debería usar:
URL('static', 'imagenes/iconos/flecha.png')
No es necesario que codifiques o escapes los argumentos en args o vars; esto se realiza automáticamente por ti.
Por defecto, la extensión correspondiente a la solicitud actual (que se puede encontrar en request.extension) se agrega a la función, a menos que request.extension sea html, el valor por defecto. Este comportamiento se puede sobrescribir incluyendo explícitamente una extensión como parte del nombre de la función URL(f='nombre.ext') o con el argumento extension:
URL(..., extension='css')
La extensión actual se puede omitir explícitamente:
URL(..., extension=False)
URL absolutos
Por defecto, URL genera URL relativas. Sin embargo, puedes además generar URL absolutas especificando los argumentos scheme y host (esto es de utilidad, por ejemplo, cuando se insertan URL en mensajes de email):
URL(..., scheme='http', host='www.misitio.com')
Puedes incluir automáticamente el scheme y host de la solicitud actual simplemente estableciendo los argumentos como True.
URL(..., scheme=True, host=True)
La función URL además acepta un argumento port para especificar el puerto del servidor si es necesario.
Firma digital de URL
Cuando generas una URL, tienes la opción de firmarlas digitalmente. Esto añadirá una variable _signature tipo GET que se puede ser verificada por el servidor. Esto se puede realizar de dos formas distintas.
Puedes pasar los siguientes argumentos a la función URL:
hmac_key: la clave para la firma del URL (una cadena)salt: una cadena opcional para utilizar la técnica salt antes de la firmahash_vars: una lista opcional de nombres de variables de la cadena de la consulta URL (query string variables, es decir, variables GET) a incluir en la firma. También se puede establecer comoTrue(por defecto) para incluir todas las variables, oFalsepara no incluir variables.
Aquí se muestra un ejemplo de uso:
KEY = 'miclave'
def uno():
return dict(link=URL('dos', vars=dict(a=123), hmac_key=KEY))
def dos():
if not URL.verify(request, hmac_key=KEY): raise HTTP(403)
# hacer algo
return locals()
Esto hace que se pueda acceder a la acción dos sólo por medio de una URL firmada digitalmente. Una URL firmada digitalmente se ve así:
'/welcome/default/dos?a=123&_signature=4981bc70e13866bb60e52a09073560ae822224e9'Ten en cuenta que la firma digital se verifica a través de la función URL.verify. URL.verify además toma los parámetros hmac_key, salt, y hash_vars descriptos anteriormente, y sus valores deben coincidir con los que se pasaron a la función URL cuando se creó la firma digital para poder verificar la URL.
Una segunda forma más sofisticada y más usual de URL firmadas digitalmente es la combinación con Auth. Esto se explica más fácilmente por medio de un ejemplo:
@auth.requires_login()
def uno():
return dict(link=URL('dos', vars=dict(a=123), user_signature=True)
@auth.requires_signature()
def dos():
# hacer algo
return locals()
En este caso la hmac_key se genera automáticamente y se comparte en la sesión. Esto permite que la acción dos delegue todo control de acceso a la acción uno. Si se genera el link y se firma, este es válido; de lo contrario no lo es. Si otro usuario se apropia del link, este no será válido.
Es una buena práctica la firma digital de todo callback de Ajax. Si usas la función LOAD, esta también tiene un argumento user_signature que se puede usar con ese fin:
{{=LOAD('default', 'dos', vars=dict(a=123), ajax=True, user_signature=True)}}HTTP and redirect
web2py define sólo una excepción llamada HTTP. Esta excepción se puede generar en cualquier parte de un modelo, controlador o vista con el comando:
raise HTTP(400, "mi mensaje")
Esto hace que el flujo del control (control flow) se salga del código del usuario, de vuelta a web2py y que devuelva una respuesta HTTP como esta:
HTTP/1.1 400 BAD REQUEST
Date: Sat, 05 Jul 2008 19:36:22 GMT
Server: Rocket WSGI Server
Content-Type: text/html
Via: 1.1 127.0.0.1:8000
Connection: close
Transfer-Encoding: chunked
mi mensaje
El primer argumento de HTTP es el código de estado HTTP. El segundo argumento es la cadena que se devolverá como cuerpo de la respuesta. Se pueden pasar otros argumentos por nombre adicionales para crear el encabezado de la respuesta HTTP. Por ejemplo:
raise HTTP(400, 'mi mensaje', test='hola')
genera:
HTTP/1.1 400 BAD REQUEST
Date: Sat, 05 Jul 2008 19:36:22 GMT
Server: Rocket WSGI Server
Content-Type: text/html
Via: 1.1 127.0.0.1:8000
Connection: close
Transfer-Encoding: chunked
test: hola
mi mensaje
Si no deseas aplicar los cambios (commit) de la transacción abierta de la base de datos, puedes anularlos (rollback) antes de generar la excepción.
Toda excepción que no sea HTTP hace que web2py anule (rollback) toda transacción de base de datos abierta, registre el error, envíe un ticket al visitante y devuelva una página de error estándar.
Esto significa que el flujo de control entre páginas sólo es posible con HTTP. Las otras excepciones se deben manejar en la aplicación, de lo contrario, web2py generará un ticket.
El comando:
redirect('http://www.web2py.com')
es básicamente un atajo de:
raise HTTP(303,
'Estás siendo redirigido a esta <a href="%s">página web</a>' % ubicacion,
Location='http://www.web2py.com')
Los argumentos por nombre del método de inicialización HTTP se traducen en directivas de encabezado HTTP, en este caso, la ubicación de destino de la redirección (target location). redirect toma un segundo argumento opcional, que es el código de estado HTTP para la redirección (por defecto 303). Para una redirección temporaria cambia ese valor a 307 o puedes cambiarlo a 301 para una redirección permanente.
La forma más usual para redirigir es la redirección a otras páginas en la misma app y (opcionalmente) pasar parámetros:
redirect(URL('index', args=(1,2,3), vars=dict(a='b')))
En el Capítulo 12 trataremos sobre los componentes de web2py. Ellos hacen solicitudes Ajax a acciones de web2py. Si la acción llamada hace un redirect, podrías necesitar que la solicitud Ajax siga la redirección o que la página completa cambie de dirección. Para este último caso, se puede establecer:
redirect(..., type='auto')
Internacionalización y Pluralización con T
El objeto T es el traductor de idiomas. Se compone de una única instancia global de la clase de web2py gluon.language.translator. Todas las cadenas fijas (string constants, y sólo ellas) deberían marcarse con T, por ejemplo:
a = T("hola mundo")
Las cadenas que se marcan con T son detectadas por web2py como traducibles y se traducirán cuando el código (en el modelo, controlador o vista) se ejecute. Si la cadena a traducir no es constante, sino que es variable, se agregará al archivo de traducción en tiempo de ejecución (runtime, salvo en GAE) para su traducción posterior.
El objeto T también admite interpolación de variables y soporta múltiples sintaxis equivalentes:
a = T("hola %s", ('Timoteo',))
a = T("hola %(nombre)s", dict(nombre='Timoteo'))
a = T("hola %s") % ('Tim',)
a = T("hola %(nombre)s") % dict(nombre='Timoteo')
La última de las sintaxis es la recomendada porque hace la traducción más fácil. La primera cadena se traduce según el archivo de idioma solicitado y la variable nombre se reemplaza independientemente del idioma.
Es posible la concatenación de cadenas traducidas y cadenas normales:
T("bla ") + nombre + T("bla")
El siguiente código también está permitido y con frecuencia es preferible:
T("bla %(nombre)s bla", dict(nombre='Timoteo'))
o la sintaxis alternativa
T("bla %(nombre)s bla") % dict(nombre='Timoteo')
En ambos casos la traducción ocurre antes de que la variable nombre sea sustituida en la ubicación de "%(nombre)s". La alternativa siguiente NO SE DEBERÍA USAR:
T("bla %(nombre)s bla" % dict(nombre='Timoteo'))
porque la traducción ocurriría después de la sustitución.
Estableciendo el idioma
El lenguaje solicitado se determina con el campo "Accepted-Language" en el encabezado HTTP, pero esta opción se puede sobrescribir programáticamente solicitando un archivo específico, por ejemplo:
T.force('it-it')
que lee el archivo de idioma "languages/it-it.py". Los archivos de idiomas se pueden crear y editar a través de la interfaz administrativa.
Además puedes forzar el uso de un idioma para cada cadena:
T("Hola Mundo", language="it-it")
En el caso de que se soliciten múltiples idiomas, por ejemplo "it-it, fr-fr", web2py intentará ubicar los archivos de traducción "it-it.py" y "fr-fr.py". Si no se encuentra ninguno de los archivos, intentará como alternativa "it.py" y "fr.py". Si estos archivos no se encuentran utilizará "default.py". Si tampoco ese archivo es encontrado, usará el comportamiento por defecto sin traducción. La regla, en una forma más general, es que web2py intenta con "xx-xy-yy.py", luego "xx-xy.py", luego "xx.py" y por último "default.py" para cada idioma "xx-xy-yy" aceptado, buscando la opción más parecida a las preferencias del usuario.
Puedes deshabilitar completamente las traducciones con
T.force(None)
Normalmente, las traducciones de cadenas se evalúan con pereza (lazily) cuando se convierte (render) la vista; por lo tanto, no se debería usar force dentro de una vista.
Es posible deshabilitar la evaluación perezosa con
T.lazy = False
De esta forma, las cadenas se traducen de inmediato con el operador T según el idioma establecido o forzado.
Además se puede deshabilitar la evaluación perezosa para cadenas individuales:
T("Hola Mundo", lazy=False)
El siguiente es un problema usual. La aplicación original está en Inglés. Supongamos que existe un archivo de traducción (por ejemplo en Italiano, "it-it.py") y el cliente HTTP declara que acepta tanto Inglés como Italiano en ese orden. Ocurre la siguiente situación inesperada: web2py no sabe que por defecto la app se escribió en Inglés (en). Por lo tanto, prefiere traducir todo al Italiano (it-it) porque únicamente detectó el archivo de traducción al Italiano. Si no hubiera encontrado el archivo "it-it.py", hubiese usado las cadenas del idioma por defecto (Inglés).
Hay dos soluciones posibles para este problema: crear el archivo de traducción al Inglés, que sería algo redundante e innecesario, o mejor, decirle a web2py qué idiomas deberían usar las cadenas del idioma por defecto (las cadenas escritas en la aplicación). Esto se hace con:
T.set_current_languages('en', 'en-en')
Esto almacena una lista de idiomas en T.current_languages que no necesitan traducción y fuerza la recarga de los archivos de idiomas.
Ten en cuenta que "it" e "it-it" son idiomas diferentes desde el punto de vista de web2py. Para dar soporte para ambos, uno necesitaría dos archivos de traducción, siempre en minúsculas. Lo mismo para los demás idiomas.
El idioma aceptado actualmente se almacena en
T.accepted_language
Traducción de variables
T(...) no sólo traduce las cadenas sino que además puede traducir los valores contenidos en variables:
>>> a="test"
>>> print T(a)
En este caso se traduce la palabra "test" pero, si no se encuentra y el sistema de archivos permite la escritura, se agregará a la lista de palabras a traducir en el archivo del idioma.
Observa que esto puede resultar en una gran cantidad de E/S de archivo y puedes necesitar deshabilitarlo:
T.is_writable = False
evita que T actualice los archivos de idioma en forma dinámica.
Comentarios y traducciones múltiples
Es posible que la misma cadena aparezca en distintos contextos en la aplicación y que necesite distintas traducciones según el contexto. Para resolver este problema, uno puede agregar comentarios a la cadena original. Los comentarios no se convierten, web2py los usará para determinar la traducción más apropiada. Por ejemplo:
T("hola mundo ## primer caso")
T("hola mundo ## segundo caso")
Los textos a la derecha de los ##, incluyendo los dobles ##, son comentarios.
El motor de pluralización
A partir de la versión 2.0, web2py incluye un potente sistema de pluralización (PS). Esto quiere decir que cuando se marque al texto para traducción y el texto dependa de una variable numérica, puede ser traducido en forma diferente según el valor numérico. Por ejemplo en Inglés podemos convertir:
x book(s)como
a book (x==1)
5 books (x==5)El idioma inglés tiene una forma para el singular y una para el plural. La forma plural se construye agregando una "-s" o "-es" o usando una forma especial. web2py provee de una forma de definir reglas de pluralización para cada lenguaje, así como también definir excepciones a esas reglas. De hecho, web2py maneja por defecto las reglas de varios idiomas, y también excepciones a sus reglas. Sabe, por ejemplo, que el esloveno tiene una forma singular y 3 formas plurales (para x==1, x==3 o x==4 y x>4). Estas reglas se establecen en los archivos "gluon/contrib/plural_rules/*.py" y se pueden crear nuevos archivos. Las pluralizaciones explícitas para las palabras se pueden crear editando los archivos de pluralización en la interfaz administrativa.
Por defecto, el sistema PS no está activado. Se activa cuando su usa el argumento symbols de la función T. Por ejemplo:
T("Tienes %s %%{libro}", symbols=10)
Ahora el sistema PS se activará para la palabra "libro" y el número 10. El resultado en Español será: "Tienes 10 libros". Observa que "libro" se ha pluralizado como "libros".
El sistema PS está compuesto por 3 partes:
- marcadores de posición
%%{}para marcar las palabras en textos procesados porT - reglas para establecer qué forma se usará ("rules/plural_rules/*.py")
- un diccionario de formas plurales de palabras "app/languages/plural-*.py"
El valor de symbols puede ser una única variable, una lista o tupla de variables o un diccionario.
El marcador de posición %%{} está compuesto por 3 partes:
%%{[<modificador>]<palabra>[<parámetro>]},donde:
<modificador>::= ! | !! | !!!
<palabra> ::= cualquier palabra o frase en singular y minúsculas (!)
<parámetro> ::= [índice] | (clave) | (número)Por ejemplo:
%%{palabra}equivale a%%{palabra[0]}(si no se usan modificadores).%%{palabra[índice]}se usa cuando symbols es una tupla. symbols[índice] nos da un número usado para establecer que forma de la palabra se debe usar.%%{palabra(clave)}se usa para recuperar el parámetro numérico en symbols[clave]%%{palabra(numero)}permite establecer unnumeroen forma directa (por ejemplo:%%{palabra(%i)})%%{?palabra?numero}devuelve "palabra" si se compruebanumero==1, de lo contrario devuelvenumero%%{?numero} or %%{??numero}devuelvenumerosinumero!=1, de lo contrario no devuelve nada
T("blabla %s %%{palabra}", symbols=var)%%{palabra} por defecto significa %%{word[0]}, donde [0] es un índice de ítem de la tupla de symbols.
T("blabla %s %s %%{palabra[1]}", (var1, var2))Se usa el PS para "palabra" y var2 respectivamente.
Puedes usar muchos marcadores de posición %%{} con el índice:
T("%%{este} %%{es} %%{el} %s %%{libro}", var)o
T("%%{este[0]} %%{es[0]} %%{el[0]} %s %%{libro[0]}", var)Estas expresiones generarán lo siguiente:
var salida
------------------
1 este es el 1 libro
2 estos son los 2 libros
3 estos son los 2 librosEn forma similar puedes pasar un diccionario a los símbolos:
T("blabla %(var1)s %(ctapalabras)s %%{word(ctapalabras)}",
dict(var1="tututu", ctapalabras=20))que producirá
blabla tututu 20 palabrasPuedes reemplazar "1" con cualquier palabra que desees usando el marcador de posición %%{?palabra?numero}. Por ejemplo
T("%%{este} %%{es} %%{?un?%s} %%{libro}", var)produce:
var salida
------------------
1 este es un libro
2 estos son 2 libros
3 estos son 3 libros
...Dentro de %%{...} puedes además usar los siguientes modificadores:
!para que la letra inicial sea mayúscula (equivale astring.capitalize)!!para que cada palabra tenga inicial mayúscula (equivale astring.title)!!!para convertir cada palabra a mayúsculas (equivale astring.upper)
Ten en cuenta que puedes usar \ para escapar ! y ?.
Traducciones, pluralización y MARKMIN
También puedes usar la potente sintaxis de MARKMIN dentro de las cadenas a traducir reemplazando
T("hola mundo")
con
T.M("hola mundo")Ahora la cadena aceptará el lenguaje de marcas MARKMIN según se describe más adelante en este libro. Además puedes usar el sistema de pluralización dentro de MARKMIN.
Cookie
web2py utiliza los módulos de Python para el manejo de las cookie.
Las cookie del navegador se encuentran en request.cookies y las cookie enviadas por el servidor están en response.cookies.
Puedes crear valores de cookie de la siguiente forma:
response.cookies['micookie'] = 'unvalor'
response.cookies['micookie']['expires'] = 24 * 3600
response.cookies['micookie']['path'] = '/'
La segunda linea le dice al navegador que conserve la cookie por 24 horas. La tercer línea le dice al navegador que envíe una cookie de regreso a cualquier aplicación en el dominio actual (ruta URL). Ten en cuenta que si no especificas la ruta para la cookie, el navegador se configurará con la ruta del URL que se solicitó, por lo que la cookie sólo se enviará de regreso al servidor cuando se solicite esa misma ruta URL.
La cookie se puede hacer segura con:
response.cookies['micookie']['secure'] = True
Esto le dice al navegador que sólo devuelva la cookie sobre HTTPS, no sobre HTTP.
La cookie se puede recuperar con:
if request.cookies.has_key('micookie'):
valor = request.cookies['micookie'].value
A menos que se deshabiliten las sesiones, web2py, como proceso interno, establece la siguiente cookie, que usa para el manejo de sesiones:
response.cookies[response.session_id_name] = response.session_id
response.cookies[response.session_id_name]['path'] = "/"
Ten en cuenta que si una aplicación determinada incluye subdominios múltiples, y quieres compartir las sesiones a través de esos subdominios (por ejemplo, sub1.tudominio.com, sub2.tudominio.com, etc.), debes establecer explícitamente el dominio de la cookie de sesión de esta forma:
if not request.env.remote_addr in ['127.0.0.1', 'localhost']:
response.cookies[response.session_id_name]['domain'] = ".tudominio.com"
El comando descripto arriba puede ser útil si, por ejemplo, quisieras permitir al usuario que permanezca autenticado para distintos dominios.
La aplicación init
Cuando despliegues (deploy) web2py, querrás establecer una aplicación por defecto, por ejemplo, la aplicación que se inicia cuando hay una ruta vacía en la URL, como en:
http://127.0.0.1:8000
Por defecto, cuando web2py se encuentra con una ruta vacía, busca una aplicación llamada init. Si no hay una aplicación init buscará una aplicación llamada welcome.
El nombre de la apliación por defecto se puede cambiar de init a otro nombre estableciendo el valor de default_application en routes.py:
default_application = "miapp"
Ten en cuenta que default_application se agregó por primera vez en la versión 1.83 de web2y.
Aquí mostramos cuatro formas de establecer la aplicación por defecto:
- Establecer el nombre de la aplicación por defecto como "init".
- Establecer
default_applicationcon el nombre de la aplicación en routes.py - Hacer un link simbólico de "applications/init" a la carpeta de la aplicación.
- Usar la reescritura de URL como se detalla en la próxima sección.
Reescritura de URL
web2py tiene la habilidad de reescribir la ruta de la URL para solicitudes entrantes antes de llamar a la acción en el controlador (mapeo de URL o URL mapping), y en el otro sentido, web2py puede reescribir la ruta de la URL generada por la función URL (mapeo reverso de URL o reverse URL mapping). Una de las razones para esto es para el soporte de las URL heredadas (legacy), otra razón es la posibilidad de simplificar las rutas y hacerlas más cortas.
web2py incluye dos sistemas de reescritura de URL: un sistema basado en parámetros de fácil uso para la mayor parte de los casos posibles, y un sistema basado en patrones para los casos más complicados. Para especificar las reglas de reescritura de URL, crea un archivo nuevo en la carpeta "web2py" llamada routes.py (el contenido de routes.py dependerá del sistema de reescritura que elijas, como se describe en las siguientes secciones). Los dos sistemas no se pueden mezclar.
Observa que si editas routes.py, debes volver a cargarlo. Esto se puede hacer en dos formas: reiniciando el servidor web o haciendo clic en el botón para cargar nuevamente routes en admin. Si hay un fallo en routes, no se actualizará.
Sistema basado en parámetros
El sistema basado en parámetros (paramétrico) provee de un acceso fácil a muchos métodos "enlatados". Entre sus posibilidades se puede enumerar:
- Omitir los nombres de la aplicación, controlador y función por defecto en las URL visibles desde afuera (las creadas por la función URL())
- Asociar (mapear) dominios (y/o puertos) a controladores de aplicaciones
- Embeber un selector de idioma en la URL
- Eliminar un prefijo determinado de las URL entrantes y añadirlo nuevamente a las URL salientes
- Asociar (mapear) archivos de la raíz como /robots.txt a un directorio estático de la aplicación
El router paramétrico también provee de una forma más flexible de validación para las URL entrantes.
Digamos que has creado una aplicación llamada miapp y deseas que sea la aplicación por defecto, de forma que el nombre de la aplicación ya no forme parte de la URL cuando la ve el usuario. Tu controlador por defecto sigue siendo default, y también quieres eliminar su nombre de la URL que ve el usuario. Esto es entonces lo que debes poner en routes.py:
routers = dict(
BASE = dict(default_application='miapp'),
)
Y eso es todo. El router paramétrico es lo suficientemente inteligente para hacer lo correcto con una URL como:
http://dominio.com/myapp/default/miapp
o
http://dominio.com/myapp/miapp/index
donde el acortamiento normal sería ambiguo. Si tienes dos aplicaciones, miappy miapp2, obtendrás el mismo efecto, y adicionalmente, el controlador por defecto de miapp2 se recortará de la URL cuando sea seguro (que es lo normal casi siempre).
Aquí hay otro caso: digamos que quieres dar soporte para lenguajes basado en URL, donde las URL son algo así:
http://miapp/es/una/ruta
o (reescrita)
http://es/una/ruta
Esta es la forma de hacerlo:
routers = dict(
BASE = dict(default_application='miapp'),
miapp = dict(languages=['en', 'it', 'jp'], default_language='es'),
)
Ahora una URL entrante como esta:
http:/dominio.com/it/una/ruta
se asociará como /miapp/una/ruta, y se establecerá request.uri_language como 'it', para que puedas forzar la traducción. Además puedes tener archivos estáticos específicos por idioma.
http://domain.com/it/static/archivo
se asociará con:
applications/miapp/static/it/archivo
si ese archivo existiera. Si no, entonces los URL como:
http://domain.com/it/static/base.css
se asociarán como:
applications/miapp/static/base.css
(porque no hay un static/it/base.css).
Entonces ahora puedes tener archivos estáticos específicos por idioma, incluyendo imágenes, si así lo necesitaras. También está soportada el mapeo de dominio (domain mapping):
routers = dict(
BASE = dict(
domains = {
'dominio1.com' : 'app1',
'dominio2.com' : 'app2',
}
),
)
cuya función es obvia.
routers = dict(
BASE = dict(
domains = {
'dominio.com:80' : 'app/insegura',
'domnio.com:443' : 'app/segura',
}
),
)
asocia los accesos al controlador llamado inseguro de http://dominio.com, mientras que los accesos con HTTPS van al controlador seguro. Como alternativa, puedes asociar distintos puertos a distintas app, con una notación análoga a la de los ejemplos anteriores.
Para más información, puedes consultar el archivo router.example.py que se incluye en la carpeta raíz de la distribución estándar de web2py.
Nota: el sistema basado en parámetros está disponible desde la versión 1.92.1 de web2py.
Sistema basado en patrones
Si bien el sistema basado en parámetros recién descripto debería de ser suficiente para la mayor parte de los casos, el sistema alternativo basado en patrones provee de flexibilidad adicional para casos más complejos. Para usar el sistema basado en patrones, en lugar de definir los enrutadores como diccionarios con parámetros de enrutamiento, se definen dos listas (o tuplas) de pares (2-tuplas), routes_in y routes_out. Cada tupla contiene dos elementos: el patrón a reemplazar y la cadena que lo reemplaza. Por ejemplo:
routes_in = (
('/pruebame', '/ejemplos/default/index'),
)
routes_out = (
('/ejemplos/default/index', '/pruebame'),
)
Con estas rutas, la URL:
http://127.0.0.1:8000/pruebame
es asociada a:
http://127.0.0.1:8000/ejemplos/default/index
Para el visitante, todos los link a la URL de la página se ven como /pruebame.
Los patrones tienen la misma sintaxis que las expresiones regulares de Python. Por ejemplo:
('.*.php', '/init/default/index'),
asocia toda URL que termine en ".php" a la página de inicio.
El segundo término de una regla también puede ser una redirección a otra página:
('.*.php', '303->http://ejemplo.com/nuevapagina'),
Aquí 303 es el código HTTP para la respuesta de redirección.
A veces queremos deshacernos del prefijo de la aplicación en las URL porque queremos exponer sólo una aplicación. Esto es posible con:
routes_in = (
('/(?P<any>.*)', '/init/\g<any>'),
)
routes_out = (
('/init/(?P<any>.*)', '/\g<any>'),
)
También hay una sintaxis alternativa que se puede mezclar con la notación anterior de expresiones regulares. Consiste en usar $nombre en lugar de (?P<nombre>\w+) o \g<nombre>. Por ejemplo:
routes_in = (
('/$c/$f', '/init/$c/$f'),
)
routes_out = (
('/init/$c/$f', '/$c/$f'),
)
también elimina el prefijo de la aplicación en todas las URL.
Si usas la notación $nombre, puedes asociar automáticamente routes_in a routes_out, siempre y cuando no uses expresiones regulares. Por ejemplo:
routes_in = (
('/$c/$f', '/init/$c/$f'),
)
routes_out = [(x, y) for (y, x) in routes_in]
Si existen múltiples rutas, se ejecuta la primera que coincida con la URL, si no hay coincidencias en el patrón, no se hacen cambios a la ruta.
Puedes usar $anything para comparar con cualquier cadena (.*) hasta el final de línea.
Aquí mostramos una versión mínima de "routes.py" para el manejo de solicitudes de favicon y robot:
routes_in = (
('/favicon.ico', '/ejemplos/static/favicon.ico'),
('/robots.txt', '/ejemplos/static/robots.txt'),
)
routes_out = ()
Este es un ejemplo más complejo que expone una sola app, "miapp", sin prefijos innecesarios y que además expone admin, appadmin y static:
routes_in = (
('/admin/$anything', '/admin/$anything'),
('/static/$anything', '/miapp/static/$anything'),
('/appadmin/$anything', '/miapp/appadmin/$anything'),
('/favicon.ico', '/miapp/static/favicon.ico'),
('/robots.txt', '/miapp/static/robots.txt'),
)
routes_out = [(x, y) for (y, x) in routes_in[:-2]]
La sintaxis general para routes es más compleja que los ejemplos básicos que hemos visto hasta ahora. Este es un ejemplo más general y representativo:
routes_in = (
('140.191.\d+.\d+:https?://www.web2py.com:post /(?P<any>.*).php',
'/prueba/default/index?vars=\g<any>'),
)
Asocia las solicitudes http o https POST (ten en cuenta el uso de minúsculas en "post") a la máquina en www.web2py.com desde una IP remota que coincide con la expresión regular
'140.191.\d+.\d+'
Si se solicita una página que coincida con la expresión
'/(?P<any>.*).php'
se asociará a
'/prueba/default/index?vars=\g<any>'
donde \g<any> es reemplazada por la expresión regular que coincida.
La sintaxis general es
'[dirección remota]:[protocolo]://[equipo (host)]:[método] [ruta]'
Si falta la primer sección del patrón (todo excepto [ruta], web2py la reemplaza con un valor por defecto:
'.*?:https?://[^:/]+:[a-z]+'
La expresión completa se compara como expresión regular, por lo que "." debe escaparse (escape) y toda subexpresión que coincida se puede capturar usando (?P<...>...), con la notación de expresiones regulares de Python. El método de la solicitud (típicamente GET o POST) debe ser en minúsculas. Además, se eliminan los delimitadores (unquote) de toda cadena de tipo %xx en la URL a comparar.
Esto permite reenrutar las solicitudes basadas en la IP o dominio del cliente, según el tipo de solicitud, tipo de método y ruta. Además permite que web2py asocie distintas máquinas virtuales (virtual host) a distintas aplicaciones. Toda subexpresión que coincida se puede usar para armar la URL de destino (target) y, eventualmente, puede ser pasada como variable GET.
Los servidores más conocidos, como Apache y lighttpd, tienen además la posibilidad de reescribir las URL. En un entorno de producción se podría optar por esa opción en lugar de routes.py. Sea cual sea tu decisión, te recomendamos que no escribas "a mano" (hardcode) las URL internas en tu app y que uses la función URL para generarlas. Esto hará tu aplicación más portátil en caso de que se realicen cambios en el enrutamiento.
Reescritura de URL específica de una aplicación
Al usar el sistema basado en patrones, una aplicación puede configurar sus propias rutas en un archivo específico routes.py ubicado en la carpeta base de la aplicación. Esto se habilita configurando routes.py en el archivo routes.py base para determinar en una URL entrante el nombre de la aplicación seleccionada. Cuando esto ocurre, se usa el routes.py específico de la aplicación en lugar del routes.py base.
El formato de routes_app es idéntico al de routes_in, excepto que el patrón de reemplazo es simplemente el nombre de la aplicación. Si al aplicar routes_app a la URL entrante no devuelve un nombre de aplicación, o el routes.py específico de la aplicación no se encuentra, se utiliza el routes.py base.
Nota: routes_app`se agregó a partir de la versión 1.83 de web2py.
Aplicación, controlador y función por defecto
Cuando se usa el sistema basado en patrones, el nombre de la aplicación, controlador y función por defecto se puede cambiar de init, default, e index respectivamente por otro nombre configurando el valor apropiado en routes.py:
default_application = "miapp"
default_controller = "admin"
default_function = "comienzo"
Nota: Estos ítems aparecieron por primera vez en la versión 1.83.
Enrutamiento y errores
También puedes usar routes.py para reenrutar las solicitudes hacia acciones especiales en caso de que ocurra un error en el servidor. Puedes especificar el mapeo (mapping) en forma global, por aplicación, por código de error o por tipo de error para cada app. Un ejemplo:
routes_onerror = [
('init/400', '/init/default/login'),
('init/*', '/init/static/falla.html'),
('*/404', '/init/static/noseencuentra.html'),
('*/*', '/init/error/index')
]
Por cada tupla, la primera cadena es comparada con "[nombre de app]/[código de error]". Si hay una coincidencia, la solicitud fallida se reenruta hacia la URL de la segunda cadena de la tupla que coincide. Si la URL de manejo de errores no es un archivo estático, se pasarán a la acción del error las siguientes variables GET:
code: el código de status HTTP (por ejemplo, 404, 500)ticket: de la forma "[nombre de app]/[número de ticket]" (o "None" si no hay un ticket)requested_uri: el equivalente derequest.env.request_urirequest_url: el equivalente derequest.url
Estas variables serán accesibles para la acción de manejo de error por medio de request.vars y se pueden usar para generar la respuesta con el error. En particular, es buena idea que la acción del error devuelva el código original de error HTTP en lugar del código de status 200 (OK) por defecto. Esto se puede hacer configurando response.status = request.vars.code. También es posible hacer que la acción del error envíe (o encole) un correo a un administrador, incluyendo un link al ticket en admin.
Los errores que no coinciden mostrarán una página de error por defecto. Esta página de error por defecto también se puede personalizar aquí (ver router.example.py y routes.example.py en la carpeta raíz de web2py):
error_message = '<html><body><h1>%s</h1></body></html>'
error_message_ticket = '''<html><body><h1>Error interno</h1>
Ticket creado: <a href="/admin/default/ticket/%(ticket)s"
target="_blank">%(ticket)s</a></body></html>'''
La primera variable contiene el mensaje de error cuando se solicita una aplicación o función inválida. La segunda variable contiene el mensaje de error cuando se crea un ticket.
routes_onerror funciona con ambos mecanismos de enrutamiento
En "routes.py" puedes además especificar una acción que se encargará de manejar los errores:
error_handler = dict(application='error',
controller='default',
function='index')
Si se especifica el error_handler, la acción se llamará sin redirigir al usuario y se encargará del manejo del error. Si la página para el manejo del error devolviera otro error, web2py cambiará al comportamiento original devolviendo respuestas estáticas.
Administración de recursos estáticos
A partir de la versión 2.1.0, web2py tiene la habilidad de administrar los recursos estáticos.
Cuando una aplicación está en etapa de desarrollo, los archivos estáticos cambian a menudo, por lo tanto web2py envía archivos estáticos sin encabezados de caché. Esto tiene como efecto secundario el "forzar" al navegador a que incluya los archivos estáticos en cada solicitud. Esto resulta en un bajo rendimiento cuando se carga la página.
En un sitio en "producción", puedes necesitar servir archivos estáticos con encabezados cache para evitar las descargas innecesarias ya que los archivos estáticos se modifican.
Los encabezados cache permiten que el navegador recupere cada archivo por única vez, ahorrando de esta forma ancho de banda y reduciendo el tiempo de descarga.
De todos modos hay un problema: ¿qué deberían declarar los encabezados cache? ¿Cuándo deberían vencer el plazo para omitir la descarga de los archivos? Cuando se sirven los archivos por primera vez, el servidor no puede pronosticar cuándo se modificarán.
Una forma manual de resolverlo es creando subcarpetas para las distintas versiones de los archivos estáticos. Por ejemplo, se puede habilitar el acceso a una versión anterior de "layout.css" en el URL "/miapp/static/css/1.2.3/layout.css". Cuando cambias el archivo, creas una nueva subcarpeta y la enlazas como "/miapp/static/css/1.2.4/layout.css".
Este procedimiento funciona pero es molesto, porque cada vez que actualices un archivo css, deberás acordarte de copiarlo a otra carpeta, cambiar el URL del archivo en tu layout.html y luego desplegar la aplicación.
La administración de recursos estáticos resuelve el problema permitiendo al desarrollador declarar la versión de un grupo de archivos estáticos que se solicitarán nuevamente solo si ha cambiado el número de versión. El número de versión se incluye en la ruta al archivo estático como en el ejemplo anterior. La diferencia con el método anterior es que el número de versión sólo se muestra en el URL, pero se aplicará al sistema de archivos.
Si quieres servir "/myapp/static/layout.css" con los encabezados cache, solo debes incluir el archivo con un URL distinto que incluya el número de versión:
/miapp/static/_1.2.3/layout.css(Ten en cuenta que el URL define un número de versión, no se muestra en ningún otro lado).
Observa que el URL comienza con "/miapp/static/", seguido del número de versión compuesto por un subguión y 3 enteros separados por puntos (como se describe en SemVer), y luego por el nombre del archivo. Además, ten en cuenta que no debes crear una carpeta "_1.2.3/".
Cada vez que el archivo estático es solicitado indicando la versión en el url, se servirá con un encabezado cache especificando un valor de vencimiento muy lejano, específicamente.
Cache-Control : max-age=315360000
Expires: Thu, 31 Dec 2037 23:59:59 GMTEsto significa que el navegador recuperará aquellos archivos por única vez, y se guardarán por un término indefinido (prácticamente sin vencimiento) en el caché del navegador. Si cambias el número de versión en el URL, esto hace que el navegador piense que está solicitando un archivo distinto, y el archivo se descarga nuevamente.
Puedes usar "_1.2.3", "_0.0.0", "_999.888.888", siempre y cuando la versión comience con un subguión seguido de tres números separados por puntos.
En desarrollo, puedes usar response.files.append(...) para enlazar los URL de los archivos estáticos. En este caso puedes incluir la parte "_1.2.3/" en forma manual, o puedes aprovechar el nuevo parámetro del objeto response:
response.static_version.
Solo incluye los archivos estáticos en la forma usual, por ejemplo
{{response.files.append(URL('static','layout.css'))}}y en el modelo establece el valor
response.static_version = '1.2.3'
Esto traducirá automáticamente cada url "/miapp/static/layout.css" en "/miapp/static/_1.2.3/layout.css" para cada archivo incluido en response.files.
A menudo en producción optas por servir archivos estáticos por medio del servidor web (apache, nginx, etc.). Debes ajustar la configuración de forma que se omita la parte que contiene "_1.2.3/".
Por ejemplo, para Apache, cambia esto:
AliasMatch ^/([^/]+)/static/(.*) /home/www-data/web2py/applications/$1/static/$2por esto:
AliasMatch ^/([^/]+)/static/(?:/_[\d]+.[\d]+.[\d]+)?(.*) /home/www-data/web2py/applications/$1/static/$2En forma similar, para Nginx, debes cambiar esto:
location ~* /(\w+)/static/ {
root /home/www-data/web2py/applications/;
expires max;
}por esto:
location ~* /(\w+)/static(?:/_[\d]+.[\d]+.[\d]+)?/(.*)$ {
alias /home/www-data/web2py/applications/$1/static/$2;
expires max;
}Ejecutando tareas en segundo plano
En web2py, cada solicitud http se sirve en un hilo (thread) propio. Los hilos se reciclan para mayor eficiencia y son administrados por el servidor web. Por seguridad, el servidor establece un tiempo límite para cada solicitud. Esto significa que las acciones no deberían correr tareas que toman demasiado tiempo, ni deberían crear nuevos hilos y tampoco deberían bifurcarse (fork) en otros procesos (esto es posible pero no recomendable).
La forma adecuada para correr tareas prolongadas es hacerlo en segundo plano. No hay una única forma de hacerlo, pero aquí describiremos tres mecanismos que vienen incorporados en web2py: cron, colas de tareas simples, y el planificador de tareas (scheduler).
Con respecto a cron, nos referimos a una funcionalidad de web2py y no al mecanismo Cron de Unix. El cron de web2py funciona también en Windows.
El cron de web2py es el método recomendado si necesitas tareas en segundo plano en tiempos programados y estas tareas toman un tiempo relativamente corto comparado con el tiempo transcurrido entre dos llamadas. Cada tarea corre en su proceso propio, y las distintas tareas pueden ejecutarse simultáneamente, pero no tienes control sobre la cantidad de tareas que se ejecutan. Si por accidente una de las tareas se superpone con sí misma, puede causar el bloqueo de la base de datos y un pico en el uso de memoria.
El planificador de tareas de web2py tiene una metodología distinta. La cantidad de procesos corriendo es fija y estos pueden correr en distintos equipos. Cada proceso es llamado obrero (worker). Cada obrero toma una tarea cuando está disponible y la ejecuta lo antes posible a partir del tiempo programado, pero no necesariamente en el momento exacto para el que se programó. No puede haber más procesos corriendo que el número de tareas programadas y por lo tanto no habrá picos del uso de memoria. Las tareas del planificador se pueden definir en modelos y se almacenan en la base de datos. El planificador de web2py no implementa una cola distribuida (distributed queue) porque se asume que el tiempo para la distribución de tareas es insignificante comparado con el tiempo para la ejecución de las tareas. Los obreros toman las tareas de la base de datos.
Las colas de tareas simples (homemade task queues) pueden ser una alternativa más simple al programador en algunos casos.
Cron
El cron de web2py provee a las aplicaciones de la habilidad para ejecutar tareas en tiempos preestablecidos, de forma independiente con la plataforma.
Para cada aplicación, la funcionalidad de cron se define en un archivo crontab:
app/cron/crontabEste sigue la sintaxis definida en ref. [cron] (con algunos agregados que son específicos de web2py).
Antes de web2py 2.1.1, cron se habilitaba por defecto y se podía deshabilitar con la opción de la línea de comandos. A partir de 2.1.1 está deshabilitado por defecto y se puede habilitar con la opción
-Y. Este cambio fue motivado por el deseo de promover el uso del nuevo planificador (que tiene un mecanismo más avanzado que cron) y también porque el uso de cron puede incidir en el rendimiento.
Esto significa que cada aplicación puede tener una configuración de cron propia y separada y que esta configuración se puede cambiar desde web2py sin modificar el sistema operativo anfitrión.
Aquí se muestra un ejemplo:
0-59/1 * * * * root python /path/to/python/script.py
30 3 * * * root *applications/admin/cron/limpieza_db.py
*/30 * * * * root **applications/admin/cron/algo.py
@reboot root *mycontroller/mifuncion
@hourly root *applications/admin/cron/expire_sessions.py
Las últimas dos líneas en este ejemplo usan extensiones a la sintaxis normal de cron que dan funcionalidad adicional de web2py.
El archivo "applications/admin/cron/expire_sessions.py" en realidad existe y viene con la app admin. Busca sesiones vencidas y las elimina. "applications/admin/cron/crontab" corre esta tarea cada hora.
Si la tarea/script tiene el prefijo asterisco (*) y termina en .py, se ejecuta en el entorno de web2py. Esto quiere decir que tendrás todos los controladores y modelos a tu disposición. Si usas dos asteriscos (**), los modelos no se ejecutarán. Este es el método recomendado para los llamados, ya que tiene una menor sobrecarga (overhead) y evita potenciales problemas de bloqueo.
Ten en cuenta que los scripts o funciones ejecutadas en el entorno de web2py requieren un db.commit() manual al final de la función o la transacción se revertirá.
web2py no genera ticket o trazas (traceback) significativas en modo consola (shell), que es el modo en el cual corre cron, por lo que debes procurar que tu código de web2py corra sin errores antes de configurarlo como tarea de cron, ya que posiblemente no podrás ver esos errores cuando se ejecuten en cron. Es más, ten cuidado con el uso de modelos: mientras que la ejecución ocurre en procesos separados, los bloqueos de base de datos se deben tener en cuenta para evitar que las páginas tengan que esperar a tareas de cron que podrían bloquear la base de datos. Utiliza la sintaxis ** si no necesitas acceso a la base de datos en tu tarea de cron.
Además puedes llamar a una función de controlador en cron, en cuyo caso no hay necesidad de especificar una ruta. El controlador y la función serán los de la aplicación de origen. Se debe tener especial cuidado con los problemas listados arriba. Ejemplo:
*/30 * * * * root *micontrolador/mifuncion
Si especificas @reboot en el primer campo del archivo crontab, la tarea correspondiente se ejecuta sólo una vez, al inicio de web2py. Puedes usar esta funcionalidad si deseas hacer caché previo, comprobaciones o configuración inicial de datos para una aplicación al inicio de web2py. Ten en cuenta que las tareas de cron se ejecutan en paralelo con la aplicación --- si la aplicación no está lista para servir solicitudes antes de que la tarea cron haya finalizado, deberías implementar las comprobaciones adecuadas. Ejemplo:
@reboot * * * * root *mycontroller/mifuncion
Según cómo estés corriendo web2py, hay cuatro modos de operación para el web2py cron.
- "soft cron": disponible en todos los modos de ejecución
- "hard cron": disponible si se usa el servidor web incorporado (directamente o a través de mod_proxy de Apache)
- "external cron": disponible si se tiene acceso al servicio de cron propio del sistema
- Sin cron
El modo por defecto es hard cron si utilizas el servidor incorporado; en el resto de los casos, es soft cron por defecto. El soft cron es el método por defecto si utilizas CGI, FASTCGI o WSGI (pero ten en cuenta que el soft cron no se habilita por defecto en el archivo wsgihandler.py provisto con web2py).
Tus tareas se ejecutarán al realizarse la primer llamada (carga de página) a web2py a partir de tiempo especificado en crontab; pero sólo luego del proceso de la página, por lo que el usuario no observará una demora. Obviamente, hay cierta incertidumbre con respecto al momento preciso en que se ejecutará la tarea, según el tráfico que reciba el servidor. Además, la tarea de cron podría interrumpirse si el servidor web tiene configurado un tiempo límite para la descarga de la página. Si estas limitaciones no son aceptables, puedes optar por external cron (cron externo). El soft cron es razonable como último recurso, pero si tu servidor permite otros métodos cron, deberían tener prioridad.
El hard cron es el método por defecto si estás utilizando el servidor web incorporado (directamente o a través de Apache con mod_proxy). El hard cron se ejecuta en un hilo paralelo, por lo que a diferencia del soft cron, no existen limitaciones con respecto a la precisión en el tiempo o a la duración de la ejecución de la tarea.
El cron externo no es la opción por defecto en ninguna situación, pero requiere que tengas acceso a los servicios cron del sistema. Se ejecuta en un proceso paralelo, por lo que ninguna de las limitaciones de soft cron tienen lugar. Este es el modo recomendado de uso de cron bajo WSGI o FASTCGI.
Ejemplo de línea a agregar al crontab del sistema, (por lo general /etc/crontab):
0-59/1 * * * * web2py cd /var/www/web2py/ && python web2py.py -J -C -D 1 >> /tmp/cron.output 2>&1
Si usas el cron externo, asegúrate de agregar o bien -J (o --cronjob, que es lo mismo) como se indica más arriba, para que web2py sepa que se ejecuta esa por medio de cron. Web2py establece estos valores internamente si se usa soft o hard cron.
Colas de tareas simples
Si bien cron es útil para correr tareas en intervalos regulares de tiempo, no es siempre la mejor solución para correr tareas en segundo plano. Para este caso web2py provee la posibilidad de correr cualquier script de Python como si estuviera dentro de un controlador:
python web2py.py -S app -M -R applications/app/private/myscript.py -A a b c
donde -S app le dice a web2py que corra "miscript.py" como "app", -M le dice a web2py que ejecute los modelos, y -A a b c le pasa los argumentos opcionales de línea de comandos sys.args=['a', 'b', 'c'] a "miscript.py".
Este tipo de proceso en segundo plano no debería ejecutarse con cron (a excepción quizás de cron y la opción @reboot) porque necesitas asegurarte de que no se correrá más de una instancia al mismo tiempo. Con cron es posible que un proceso comience en la iteración 1 y no se complete para la iteración 2, por lo que cron vuelve a comenzar, y nuevamente, y otra vez - atascando de este modo el servidor.
En el capitulo 8, damos un ejemplo de cómo usar el método anterior para enviar email.
Planificador de tareas (Scheduler, experimental)
El planificador de tareas de web2py funciona en forma muy similar a la cola de tareas descripta en la subsección anterior con algunas particularidades:
- Provee de un mecanismo estándar para crear y programar y monitorear tareas.
- No hay un único proceso en segundo plano sino un conjunto de procesos obreros.
- El trabajo de un obrero se puede supervisar porque sus estados, así como también los estados de cada tarea, se almacenan en la base de datos.
- Funciona sin web2py pero los detalles no están documentados aquí.
El planificador no usa cron, sin embargo se podría usar el @reboot de cron para iniciar los nodos de los obreros.
Se pueden consultar instrucciones para desplegar el planificador con Linux o Windows en el capítulo de recetas de implementación.
En el planificador, una tarea es simplemente una función definida en un modelo (o en un módulo e importada en un modelo). Por ejemplo:
def tarea_sumar(a,b):
return a+b
Las tareas siempre se llamarán en el mismo entorno configurado para los controladores y por lo tanto ven todas las variables globales definidas en los modelos, incluyendo las conexiones a bases de datos (db). Las tareas se diferencian de las acciones en controladores en que no están asociadas con una solicitud HTTP y por lo tanto no hay un objeto request.env.
Recuerda que debes ejecutar
db.commit()al final de cada tarea si contiene comandos de modificación de la base de datos. web2py por defecto aplica los cambios a las bases de datos al finalizar las acciones, pero las tareas del planificador no son acciones.
Para habilitar el planificador debes instanciar la clase Scheduler en un modelo. La forma recomendable de habilitar el planificador para tu aplicación es crear un archivo del modelo llamado scheduler.py y definir tu función allí. Luego definir las funciones, puedes usar el siguiente código en el modelo:
from gluon.scheduler import Scheduler
planificador = Scheduler(db)
Si tus tareas están definidas en un módulo (en lugar de usar un modelo) puedes necesitar reiniciar los obreros.
La tarea se planifica con
planificador.queue_task(tarea_sumar, pvars=dict(a=1, b=2))
Parámetros
El primer argumento de la clase Scheduler debe ser la base de datos que usará el planificador para comunicarse con los obreros. Puede ser la db de la app u otra db especial para el planificador, quizás una base de datos compartida por múltiples aplicaciones. Si usas SQLite es recomendable el uso de bases de datos distintas para los datos de la app y para el registro de las tareas para que la app continúe respondiendo normalmente. Una vez que se han definido las tareas y creado la instancia de Scheduler, solo hace falta iniciar los obreros. Puedes hacerlo de varias formas:
python web2py.py -K miappinicia un obrero para la app miapp. Si quieres iniciar múltiples obreros para la misma app, puedes hacerlo con solo pasar myapp, myapp como argumentos. Además puedes pasar el argumento group_names (sobrescribiendo el definido en el tu modelo) con
python web2py.py -K miapp:grupo1:grupo2,miotraapp:grupo1Si tienes un modelo llamado scheduler.py puedes iniciar o parar a los obreros desde la ventana por defecto de web2py (la que usas para establecer la dirección ip y el puerto).
Otra mejora interesante: si usas el servidor web incorporado, puedes iniciarlo junto con el planificador con una única línea de código (se asume que no quieres que se muestre ventana de inicio, de lo contrario puedes usar el menú "Schedulers")
python web2py.py -a contraseña -K miapp -XPuedes pasar los parámetros usuales (-i, -p, aquí -a evita que la ventana se muestre), usa una app en el parámetro -K y agrega un -X. ¡El planificador correrá en conjunto con el servidor web!
La lista completa de los argumentos que acepta el planificador es:
Scheduler(
db,
tasks=None,
migrate=True,
worker_name=None,
group_names=None,
heartbeat=HEARTBEAT,
max_empty_runs=0,
discard_results=False,
utc_time=False
)
Vamos a detallarlos en orden:
dbes la instancia de base de datos DAL donde se crearán las tablas del planificador.taskses un diccionario que asocia nombres a funciones. si no usas este parámetro, la función se recuperará del entorno de la aplicación.worker_namees por defecto None. Tan pronto como se inicie el obrero, se generará un nombre de obrero de tipo anfitrión-uuid. Si quieres especificarlo, asegúrate de que sea único.group_namesse establece por defecto como [main]. Todas las tareas tienen un parámetrogroup_name, que es por defecto main. Los obreros solo pueden tomar tareas de su propio grupo.
Nota importante: Esto es útil si tienes distintas instancias de obreros (por ejemplo en distintas máquinas) y quieres asignar tareas a un obrero específico.
Otra nota importante: Es posible asignar más grupos a un obrero, y ellos pueden también ser todos iguales, como por ejemplo
['migrupo', 'migrupo']. Las tareas se distribuirán teniendo en cuenta que un obrero con grupos['migrupo', 'migrupo']es capaz de procesar el doble de tareas que un obrero con grupos['migrupo'].
heartbeatse configura por defecto en 3 segundos. Este parámetro es el que controla cuán frecuentemente un planificador comprobará su estado en la tablascheduler_workery verá si existe alguna tarea pendiente de procesamiento con el valor ASSIGNED (asignada) para él.max_emtpty_runses por defecto 0; eso significa que el obrero continuará procesando tareas siempre que contengan el valor ASSIGNED. Si configuras este parámetro como un valor, digamos, 10, un obrero finalizará instantáneamente si su valor es ACTIVE y no existen tareas con el valor ASSIGNED para ese obrero en un plazo de 10 iteraciones. Una iteración se entiende como el proceso de un obrero de búsqueda de tareas que tiene una frecuencia de 3 segundos (o el valor establecido paraheartbeat).discard_resultses por defecto False. Si se cambia a True, no se crearán registros scheduler_run.
Nota importante: los registros scheduler_run se crearán como antes para las tareas con los valores de estado FAILED, TIMEOUT y STOPPED tasks's.
utc_timees por defecto False. Si necesitas coordinar obreros que funcionan con distintos husos horarios, o no tienes problemas con la hora de verano o solar, utilizando fechas y horas de distintos países, etc., puedes configurarlo como True. El planificador respetará la hora UTC y funcionará omitiendo la hora local. Hay un detalle: debes programar las tareas con la hora de UTC (para los parámetros start_time, stop_time, y así sucesivamente).
Ahora tenemos la infraestructura que necesitábamos: hemos definido las tareas, hemos informado al planificador sobre ellas e iniciamos el obrero o los obreros. Lo que queda por hacer es la planificación de las tareas en sí.
Tareas
Las tareas se pueden planificar en forma programática o a través de appadmin. De hecho, una tarea se planifica simplemente agregando una entrada en la tabla "scheduler_task", a la que puedes acceder a través de appadmin:
http://127.0.0.1:8000/miapp/appadmin/insert/db/scheduler_taskEl significado de los campos en esta tabla es obvio. Los campos "args" y "vars" son los valores a pasarse a la tarea en formato JSON. En el caso de "tarea_sumar" previo, un ejemplo de "args" y "vars" podría ser:
args = [3, 4]
vars = {}
o
args = []
vars = {'a':3, 'b':4}
La tabla scheduler_task es la tabla donde se organizan las tareas.
Todas las tareas siguen un ciclo vital
Por defecto, cuando envías una tarea al planificador, este tiene el estado QUEUED. Si necesitas que este se ejecute más tarde, usa el parámetro start_time (por defecto es now). Si por alguna razón necesitas asegurarte de que la tarea no se ejecutará antes de cierto horario (quizás una consulta a un webservice que cierra a la 1 de la mañana, un correo que no se deba enviar al terminar el horario laboral, etc ...) puedes hacerlo estableciendo el parámetro stop_time (por defecto es None). Si tu tarea NO es tomada por otro obrero antes de stop_time, se establecerá como EXPIRED. Las tareas que no tengan un valor stop_time configurado o tomadas antes que el parámetro stop_time se asignan a un obrero estableciendo el valor ASSIGNED. Cuando un obrero toma una tarea, su estado se establece como RUNNING.
Las tareas que se ejecuten pueden dar como resultado los siguientes valores:
- TIMEOUT cuando hayan pasado más de
nsegundos especificados con el parámetrotimeout(por defecto 60 segundos). - FAILED cuando se detecta una excepción.
- COMPLETED cuando se completan en forma exitosa.
Los valores para start_time y stop_time deberían ser objetos datetime. Para programar la ejecución de "mitarea" en un plazo de 30 segundos a partir de la hora actual, por ejemplo, tendrías que hacer lo siguiente:
from datetime import timedelta as timed
planificador.queue_task('mitarea',
start_time=request.now + timed(seconds=30))
En forma complementaria, puedes controlar la cantidad de veces que una tarea se debe repetir (por ejemplo, puedes necesitar calcular la suma de ciertos datos con una frecuencia determinada). Para hacerlo, establece el parámetro repeats (por defecto es 1, es decir, una sola vez, si se establece 0, se repite indefinidamente). Puedes especificar la cantidad de segundos que deben pasar con el parámetro period (que por defecto es 60 segundos).
El período de tiempo no se calcula entre la finalización de la primer tanda y el comienzo de la próxima, sino entre el tiempo de inicio de la primera tanda y el tiempo de inicio del ciclo que le sigue).
Además puedes establecer la cantidad de veces que una función puede generar una excepción (por ejemplo cuando se recuperan datos de un webservice lento) y volver a incluirse en la cola en lugar de detenerse con el estado FAILED si usas el parámetro retry_failed (por defecto es 0, usa -1 para no detenerse).
Resumiendo: dispones de
periodyrepeatspara replanificar automáticamente una funcióntimeoutpara asegurarte que la función no exceda una cierta cantidad de tiempo de ejecuciónretry_failedpara controlar cuantas veces puede fallar una tareastart_timeystop_timepara planificar una función en un horario restringido
queue_task y task_status
El método:
scheduler.queue_task(function, pargs=[], pvars={}, **kwargs)
te permite agregar a la cola tareas a ejecutar por obreros. Acepta los siguientes parámetros:
function(obligatorio): puede ser el nombre de la tarea o una referencia a la función en sí.pargs: son los argumentos que se deben parar a la tarea, almacenados como una lista de Python.pvars: son los pares de argumentos nombre-valor que se usarán en la tarea, almacenados como diccionario de Python.kwargs: otras columnas de scheduler_task que se pueden pasar como argumentos de par nombre-valor (por ejemplo repeats, period, timeout).
Por ejemplo:
scheduler.queue_task('demo1', [1, 2])hace exactamente lo mismo que
scheduler.queue_task('demo1', pvars={'a':1, 'b':2})
y lo mismo que
st.validate_and_insert(function_name='demo1', args=json.dumps([1, 2]))
y que:
st.validate_and_insert(function_name='demo1', vars=json.dumps({'a':1, 'b':2}))
He aquí un ejemplo más complejo y completo:
def tarea_sumar(a, b):
return a + b
planificador = Scheduler(db, tasks=dict(demo1=tarea_sumar))
scheduler.queue_task('demo1', pvars=dict(a=1, b=2),
repeats = 0, period = 180)
Desde la versión 2.4.1, si pasas el argumento adicional inmediate=True hará que el obrero principal reorganice las tareas. Antes de 2.4.1, el obrero verificaba las nuevas tareas cada 5 ciclos (o sea, 5*heartbeat segundos). Si tenías una app que necesitaba comprobar frecuentemente nuevas tareas, para lograr un comportamiento ágil estabas obligado a disminuir el parámetro heartbeat, exigiendo a la base de datos injustificadamente. Con inmediate=True puedes forzar la comprobación de nuevas tareas: esto ocurrirá cuando hayan transcurrido n segundos, con n equivalente al valor establecido para heartbeat.
Una llamada a planificador.queue_task devuelve el id y el uudi de la tarea que has agregado a la cola (puede ser un valor que le hayas asignado o uno generado automáticamente), y los erroes posibles errors:
<Row {'errors': {}, 'id': 1, 'uuid': '08e6433a-cf07-4cea-a4cb-01f16ae5f414'}>Si existen errores (usualmente errores sintácticos o de validación de los argumentos de entrada), obtienes el resultado de la validación, e id y uuid serán None
<Row {'errors': {'period': 'ingresa un entero mayor o igual a 0'}, 'id': None, 'uuid': None}>Salida y resultados
La tabla "scheduler_run" almacena los estados de toda tarea en ejecución. Cada registro hace referencia a una tarea que ha sido tomada por un obrero. Una tarea puede ejecutarse más de una vez. Por ejemplo, una tarea programada para repetirse 10 veces por hora probablemente se ejecute 10 veces (a menos que una falle o que tomen en total más de una hora). Ten en cuenta que si la tarea no devuelve valores, se elimina de la tabla scheduler_run una vez que finalice.
Los posibles estados son
RUNNING, COMPLETED, FAILED, TIMEOUTSi se completa la ejecución, no se generaron excepciones y no venció la tarea, la ejecución se marca como COMPLETED y la tarea se marca como QUEUED o COMPLETED según si se supone que se debe ejecutar nuevamente o no. La salida de la tarea se serializa como JSON y se almacena en el registro de ejecución.
Cuando una tarea con estado RUNNING genera un excepción, tanto la ejecución como la tarea se marcan con FAILED. La traza del error se almacena en el registro.
En una forma similar, cuando una ejecución supera el plazo de vencimiento, se detiene y tanto la ejecución como la tarea se marcan con TIMEOUT.
En todo caso, se captura el stdout y además se almacena en el registro de la ejecución.
Usando appadmin, uno puede comprobar todas las tareas en ejecución RUNNING, la salida de las tareas finalizadas COMPLETE, el error en las tareas FAILED, etc.
El planificador también crea una tabla más llamada "scheduler_worker", que almacena el heartbeat de los obreros y sus estados.
Administración de procesos
El manejo pormenorizado de los obreros es difícil. Este módulo intenta una implementación común para todas las plataformas (Mac, Win, Linux).
Cuando inicias un obrero, puedes necesitar en algún momento:
- matarlo "sin importar lo que esté haciendo"
- matarlo solo si no está procesando tareas
- desactivarlo
Quizás tengas todavía algunas tareas en la cola, y quieres ahorrar recursos. Sabes que las quieres procesar a cada hora, por lo que necesitarás:
- procesar todas las tareas y finalizar automáticamente
Todas estas cosas son posibles administrando los parámetros de Scheduler o la tabla scheduler_worker. Para ser más precisos, para los obreros que han iniciado puedes cambiar el valor de estado de cualquiera para modificar su comportamiento. Igual que con las tareas, los obreros pueden tener uno de los siguientes estados: ACTIVE, DISABLED, TERMINATE or KILLED.
ACTIVE y DISABLED son "permanentes", mientras que TERMINATE o KILL, como sugieren los nombres de estado, son más bien "comandos" antes que estados.
El uso de la combinación de teclas ctrl+c equivale a establecer un estado de obrero como KILL
Hay algunas funciones convenientes a partir de la versión 2.4.1 (que no necesitan mayor descripción).
scheduler.disable() # deshabilitar
scheduler.resume() # continuar
scheduler.terminate() # finalizar
scheduler.kill() # matar
cada función toma un parámetro opcional, que puede ser una cadena o una lista, para administrar obreros según sus grupos group_names. Por defecto es equivalente a los valores de group_names, definidos crear la instancia del planificador.
Un ejemplo es mejor que cien palabras: scheduler.terminate('alta_prioridad') CANCELARÁ todos los obreros que estén procesando tareas alta_prioridad, mientras que sheduler.terminate(['alta_prioridad', 'baja_prioridad']) cancelará todos los obreros alta_prioridad y baja_prioridad.
Cuidado: si tienes un obrero procesando
alta_prioridadybaja_prioridad,scheduler.terminate('alta_prioridad')cancelará el obrero para todo el conjunto, incluso si no quieres cancelar las tareasbaja_prioridad.
Todo lo que se puede hacer a través de appadmin también puede hacerse insertando o modificando los registros de esas tablas.
De todas formas, uno no debería modificar registros relacionados con tareas en ejecución RUNNING ya que esto puede generar un comportamiento inesperado. Es mejor práctica agregar tareas a la cola usando el método "queue_task".
Por ejemplo:
scheduler.queue_task(
function_name='tarea_sumar',
pargs=[],
pvars={'a':3,'b':4},
repeats = 10, # correr 10 veces
period = 3600, # cada 1 hora
timeout = 120, # debería tomar menos de 120 segundos
)
Observa que los campos "times_run", "last_run_time" y "assgned_worker_name" no se especifican al programarse sino son completados automáticamente por los trabajadores.
También puedes recuperar la salida de las tareas completadas:
ejecuciones_finalizadas = db(db.scheduler_run.run_status='COMPLETED').select()
El planificador se considera en fase experimental porque puede necesitar pruebas más intensivas y porque la estructura de tablas puede cambiar en caso de agregarse más características.
Informando porcentajes
Hay una palabra especial para los comandos print en tus funciones que limpia toda la salida anterior. Esa palabra es !clear!. Esto, combinado con el parámetro sync_output, permite generar informes de porcentajes.
He aquí un ejemplo:
def informe_de_porcentajes():
time.sleep(5)
print '50%'
time.sleep(5)
print '!clear!100%'
return 1La función informe_de_porcentajes está inactiva durante 5 segundos, luego devuelve 50%. Entonces, cesa la actividad por otros 5 segundos y por último devuelve 100%. Ten en cuenta que la salida en la tabla sheduler_run se sincroniza cada dos segundos y que el segundo comando print que contiene !clear!100% hace que se limpie el 50% y se reemplace por 100%.
scheduler.queue_task(informe_de_porcentajes,
sync_output=2)
Módulos de terceros
web2py está desarrollado en Python, por lo que puede importar y utilizar cualquier módulo de Python, incluyendo los módulos de terceros. Sólo necesita poder hallarlos. Como con cualquier aplicación de Python, los módulos se pueden instalar en la carpeta oficial de Python "site-packages", y se pueden importar desde cualquier ubicación en tu código.
Los módulos en la carpeta "site-packages" son, como lo sugiere el nombre, paquetes del entorno/sistema. Las aplicaciones que requieren estos paquetes no son portátiles a menos que esos módulos se instalen por separado. La ventaja del uso de módulos en "site-packages" es que las distintas aplicaciones los pueden compartir. Consideremos, por ejemplo, un paquete para ploteo llamado "matplotlib". Puedes instalarlo desde la consola usando el comando easy_install de PEAK[easy-install] (o la alternativa más moderna pip [PIP]):
easy_install py-matplotlib
y luego puedes importarlo en un modelo/controlador/vista con:
import matplotlib
La distribución de código fuente de web2py y la distribución binaria de Windows tiene un site-packages en la carpeta raíz. La distribución binaria para Mac tiene una carpeta site-packages en la ruta:
web2py.app/Contents/Resources/site-packages
El problema al usar site-packages es que se torna difícil el uso de distintas versiones de un mismo módulo al mismo tiempo, por ejemplo podría haber dos aplicaciones que usen distintas versiones del mismo archivo. En este ejemplo, sys.path no se puede alterar porque afectaría a ambas aplicaciones.
Para estas situaciones, web2py provee de otra forma de importar módulos de forma que el sys.path global no se altere: ubicándolos en la carpeta "modules" de una aplicación determinada. Una ventaja de esta técnica es que el módulo se copiará y distribuirá automáticamente con la aplicación.
Una vez que un módulo "mimodulo.py" se ubica en la carpeta "modules/" de una app, se puede importar desde cualquier ubicación dentro de una aplicación de web2py (sin necesidad de modificar
sys.path) con:import mimodulo
Entorno de ejecución
Si bien todo lo descripto aquí es válido, es recomendable armar la aplicación usando componentes, como se detalla en el capítulo 12.
Los archivos de modelo y controlador no son módulos de Python en el sentido de que no se pueden importar usando la instrucción import. La razón es que los modelos y controladores están diseñados para ejecutarse en un entorno preparado que se ha preconfigurado con los objetos globales de web2py (request, response, session, cache y T) y funciones ayudantes. Esto es necesario porque Python es un lenguaje de espacios estáticos (statically -lexically- scoped language), mientras que el entorno de web2py se crea en forma dinámica.
web2py provee de una función exec_environment que te permite acceder a los modelos y controladores directamente. exec_evironment crea un entorno de ejecución de web2py, carga el archivo en él y devuelve un objeto Storage que contiene el entorno. El objeto Storage además sirve como mecanismo de espacio de nombres. Todo archivo de Python diseñado para que corra en el entorno de ejecución se puede cargar con exec_environment. Los usos de exec_environment incluyen:
- Acceso a datos (modelos) desde otras aplicaciones.
- Acceso a objetos globales desde otros modelos o controladores.
- Ejecución de funciones de otros controladores.
- Carga de librerías de ayudantes para todo el sitio/sistema.
El siguiente ejemplo lee registros de la tabla user en la aplicación cas:
from gluon.shell import exec_environment
cas = exec_environment('applications/cas/models/db.py')
registros = cas.db().select(cas.db.user.ALL)
Otro ejemplo: supongamos que tenemos un controlador "otro.py" que contiene:
def una_accion():
return dict(direccion_remota=request.env.remote_addr)
Esto se puede llamar desde otra acción de la siguiente forma (o desde la consola de web2py):
from gluon.shell import exec_environment
otro = exec_environment('applications/app/controllers/otro.py', request=request)
resultado = otro.una_accion()
En la línea 2, request=request es opcional. Tiene el efecto de pasar la solicitud actual al entorno de "otro". Sin ese argumento, el entorno contendría un objeto request nuevo y vacío (excepto por request.folder). También es posible pasar un objeto response y session a exec_environment. Ten cuidado al pasar los objetos request, response y session --- las modificaciones en la acción llamada o sus dependencias pueden dar lugar a efectos no esperados.
La llamada a la función en la línea 3 no ejecuta la vista; sólo devuelve el diccionario a menos que response.render se llame explícitamente por "una_accion".
Un detalle más a observar: no utilices exec_environment en forma inapropiada. Si quieres que los resultados de las acciones se recuperen en otra aplicación, probablemente deberías implementar una API XML-RPC (la implementación de una API XML-RPC con web2py es prácticamente trivial). No utilices exec_environment como mecanismo de redirección; utiliza el ayudante redirect.
Cooperación
Hay varias formas de cooperación entre aplicaciones:
- Las aplicaciones pueden conectarse a la misma base de datos y por lo tanto, compartir las tablas. No es necesario que todas las tablas en la base de datos se definan en cada aplicación, pero se deben definir en las aplicaciones que las usan. Todas las aplicaciones que usan la misma tabla excepto una de las aplicaciones, deben definir la tabla con
migrate=False. - Las aplicaciones pueden embeber componentes desde otras aplicaciones usando el ayudante LOAD (descripto en el capítulo 12).
- Las aplicaciones pueden compartir sesiones.
- Las aplicaciones pueden llamar a las acciones de otras aplicaciones en forma remota a través de XML-RPC.
- Las aplicaciones pueden acceder a los archivos de otras aplicaciones a través del sistema de archivos (se asume que las aplicaciones comparten el sistema de archivos).
- Las aplicaciones pueden llamar a las acciones de otras aplicaciones en forma local utilizando
exec_environmentcomo se detalla más arriba. - Las aplicaciones pueden importar módulos de otras aplicaciones usando la sintaxis:
from applications.nombreapp.modules import mimodulo
- Las aplicaciones pueden importar cualquier módulo en las rutas de búsqueda del
PYTHONPATHysys.path. - Una app puede cargar la sesión de otra app usando el comando:
session.connect(request, response, masterapp='nombreapp', db=db)
Aquí "nombreapp" es el nombre de la aplicación maestra, es decir, la que establece la sesión_id inicial en la cookie. db es una conexión a la base de datos que contiene la tabla de la sesión (web2py_session). Todas las app que comparten sesiones deben usar las misma base de datos para almacenar las sesiones.
- Una aplicación puede cargar un módulo desde otra app usando
import applications.otraapp.modules.otromodulo
Historial o logging
Python provee de distintas API para historial o logging. web2py dispone de un mecanismo para configurarlo para que las app lo puedan usar.
En tu aplicación, creas un logger, por ejemplo en un modelo:
import logging
logger = logging.getLogger("web2py.app.miapp")
logger.setLevel(logging.DEBUG)
y puedes usarlo para registrar (log) mensajes de distinta importancia
logger.debug("Sólo comprobando que %s" % detalles)
logger.info("Deberías saber que %s" % detalles)
logger.warn("Cuidado que %s" % detalles)
logger.error("Epa, algo malo ha ocurrido %s" % detalles)
logging es un módulo estándar de Python que se detalla aquí:
http://docs.python.org/library/logging.htmlLa cadena "web2py.app.miapp" define un logger en el nivel de la aplicación.
Para que esto funcione adecuadamente, necesitas un archivo de configuración para el logger. Hay un archivo incluido en la instalación de web2py en la carpeta raíz, "logging.example.conf". Debes cambiar el nombre del archivo como "logging.conf" y personalizarlo según tus requerimientos.
Este archivo contiene documentación de uso, por lo que es conveniente que lo abras y lo leas.
Para crear un logger configurable para la aplicación "miapp", debes agregar miapp a la lista de claves [loggers]:
[loggers]
keys=root,rocket,markdown,web2py,rewrite,app,welcome,miapp
y debes agregar una sección [logger_miapp], usando [logger_welcome] como ejemplo.
[logger_myapp]
level=WARNING
qualname=web2py.app.miapp
handlers=consoleHandler
propagate=0
La directiva "handlers" especifica el tipo de historial y, para el ejemplo, la salida del historial para miapp se muestra por consola.
WSGI
web2py y WSGI tienen una relación de amor-odio. Nuestra opinión es que WSGI fue desarrollado como protocolo para conectar servidores web a aplicaciones web en forma portátil, y lo usamos con ese fin. web2py en su núcleo es una aplicación WSGI: gluon.main.wsgibase. Algunos desarrolladores han llevado a WSGI a sus límites como protocolo para comunicaciones middleware y desarrollan aplicaciones web en forma de cebolla, con sus múltiples capas (cada capa es un middleware desarrollado en forma independiente de la totalidad del marco de desarrollo). web2py no adopta esta estructura en forma interna. Esto se debe a que creemos que las funcionalidades del núcleo de los marcos de desarrollo (manejo de las cookie, sesión, errores, transacciones, manejo de las URL o dispatching) se pueden optimizar para que sean más seguras y veloces si son manejadas por una única capa que las incluya.
De todos modos, web2py te permite el uso de aplicaciones WSGI de terceros y middleware en tres formas (y sus combinaciones):
- Puedes editar el archivo "wsgihandler.py" e incluir cualquier middleware WSGI de terceros.
- Puedes conectar middleware WSGI de terceros a cualquier acción específica en tus app.
- Puedes llamar a una app WSGI de terceros desde tus acciones.
La única limitación es que no puedes usar middleware de terceros para reemplazar las funciones del núcleo de web2py.
Middleware externo
Consideremos el archivo "wsgibase.py":
#...
LOGGING = False
#...
if LOGGING:
aplicacion = gluon.main.appfactory(wsgiapp=gluon.main.wsgibase,
logfilename='httpserver.log',
profilerfilename=None)
else:
aplicacion = gluon.main.wsgibase
Cuando LOGGING se establece como True, gluon.main.wsgibase es envuelto (wrapped) por la función middleware gluon.main.appfactory. Esta provee de registro del historial en el archivo "httpserver.log". En forma similar puedes agregar cualquier middleware de terceros. Se puede encontrar más información sobre este tema en la documentación oficial de WSGI.
Middleware interno
Dada cualquier acción en tus controladores (por ejemplo index) y cualquier aplicación middleware de terceros (por ejemplo MiMiddleware, que convierte la salida a mayúsculas), puedes usar un decorador de web2py para aplicar el middleware a esa acción. Este es un ejemplo:
class MiMiddleware:
"""Convertir la salida a mayúsculas"""
def __init__(self, app):
self.app = app
def __call__(self, entorno, iniciar_respuesta):
elementos = self.app(entorno, iniciar_respuesta)
return [item.upper() for item in elementos]
@request.wsgi.middleware(MyMiddleware)
def index():
return 'hola mundo'
No podemos garantizar que todo middleware de terceros funcione con este mecanismo.
Llamando a aplicaciones WSGI
Es fácil llamar a una app WSGI desde una acción en web2py. Este es un ejemplo:
def probar_app_wsgi(entorno, iniciar_respuesta):
"""Esta es una app WSGI para prueba"""
estado = '200 OK'
encabezados_respuesta = [('Content-type','text/plain'),
('Content-Length','13')]
iniciar_respuesta(estado, encabezados_respuesta)
return ['¡hola mundo!\n']
def index():
"""Una acción para prueba que llama a la app previa y escapa la salida"""
elementos = probar_app_wsgi(request.wsgi.environ,
request.wsgi.start_response)
for item in elementos:
response.write(item, escape=False)
return response.body.getvalue()
En este caso, la acción index llama a probar_app_wsgi y escapa el valor obtenido antes de devolverlo. Observa que index por sí misma no es una app WSGI y debe usar la API normal de web2py (por ejemplo response.write para escribir en el socket).